Text size
Line height
Text spacing


A computer cluster consists of a multitude of nodes fairly closely connected to a network. Nodes work in the same way and consist of the same elements as found in personal computers: processors, memory, and input / output units. Clusters, of course, predominate in the quantity, performance, and quality of the built-in elements, but they usually do not have input-output devices such as a keyboard, mouse, and screen.
We distinguish several types of nodes in clusters, their structure depends on their role in the system. The following are important for the user:
Computer cluster software consists of:
An operating system is a bridge between user software and computer hardware. It is software that performs basic tasks such as: memory management, processor management, device control, file system management, implementation of security
functions, system operation control, resource consumption monitoring, error detection. Popular operating systems are free Linux, paid macOS and Windows. The CentOS Linux operating system is installed on the nodes of the NSC, Maister,
and Trdina clusters.
Middleware is software that clusters the operating system and user applications. In the computer cluster, it takes care of the coordinated operation of a multitude of nodes, enables centralized management of nodes, takes care of user authentication,
controls the execution of transactions (user applications) on nodes and the like. Users of computer clusters mostly work with middleware for business monitoring, and SLURM (Simple Linux Utility for Resource Management) is very widespread.
The Slurm system manages the queue, allocates the required resources to the business and monitors the execution of business. With the Slurm system, users provide access to resources (computing nodes) for a certain period of time, start
transactions and monitor their implementation.
User software is the key software that makes us use computers, both regular and computer clusters. With the user software, users perform the desired functions. Only user software adapted for the Linux operating system can be used on clusters.
Some examples of user software used on clusters: Gromacs for molecular dynamics simulations, OpenFOAM for fluid flow simulations, Athena collision analysis software on the LHC collider at CERN (ATLAS), TensorFlow for learning deep
models in artificial intelligence. In the workshop, we will use the FFmpeg video processing tool.
User software can be clustered in a variety of ways:
To make system maintenance easier, administrators install the user software in the form of environmental modules, preferably in the form of containers.
When logging in to the cluster, we find ourselves in the command line with the standard environment settings. This environment can be supplemented for easier work, most simply with environmental modules. Environmental modules are a tool
for changing command line settings and allow users to easily change the environment while working.
Each environment module file contains the information needed to set the command line for the selected software. When we load the environment module, we adjust the environment variables to run the selected user software. One such variable
is PATH, which lists the folders where the operating system searches for programs.
The environmental modules are installed and updated by the cluster administrator. By preparing environmental modules for the software, it facilitates maintenance, avoids installation problems due to the use of different versions of libraries,
and the like. The prepared modules can be loaded and removed by the user during work.
As we have seen, we have a multitude of processor cores on nodes that can run a multitude of user applications simultaneously. When installing user applications directly on the operating system, it can get stuck, mostly due to improper
versions of libraries.
Node virtualization is an elegant solution that ensures the coexistence of a wide variety of user applications and therefore easier system management. The capacity of the system is slightly lower due to virtualization, of course
at the expense of greater robustness and ease of system maintenance. We distinguish between hardware virtualization and operating system virtualization. In the first case we are talking about virtual machines (virtual machines), in
the second about containers (containers).
Container virtualization is more suitable for supercomputer clusters. The containers do not include the operating system, so they are smaller and it is easier for the controller to switch
between them. The container supervisor keeps the containers isolated from each other and gives each container access to a common operating system and core libraries. Only the necessary user software and additional libraries are then
installed separately in each container.
Computer cluster administrators want users to use containers as much as possible, because:
Docker containers are the most common. On the mentioned clusters, a Singularity controller is installed for working with containers, which is more adapted for work in a supercomputer environment. In the Singularity container environment,
we can work with the same user account as on the operating system, we have organized access to the network and data. The Singularity monitor can run Docker and other containers.
Dear hackathon attendee,
on Day 2 of the hackathon we will open a survey to get your feedback about the event. The survey is a standard ELIXIR short-term feedback survey and its results will be uploaded to the ELIXIR Training Metrics Database. The survey is anonymous.
bbb.mp41 to the cluster.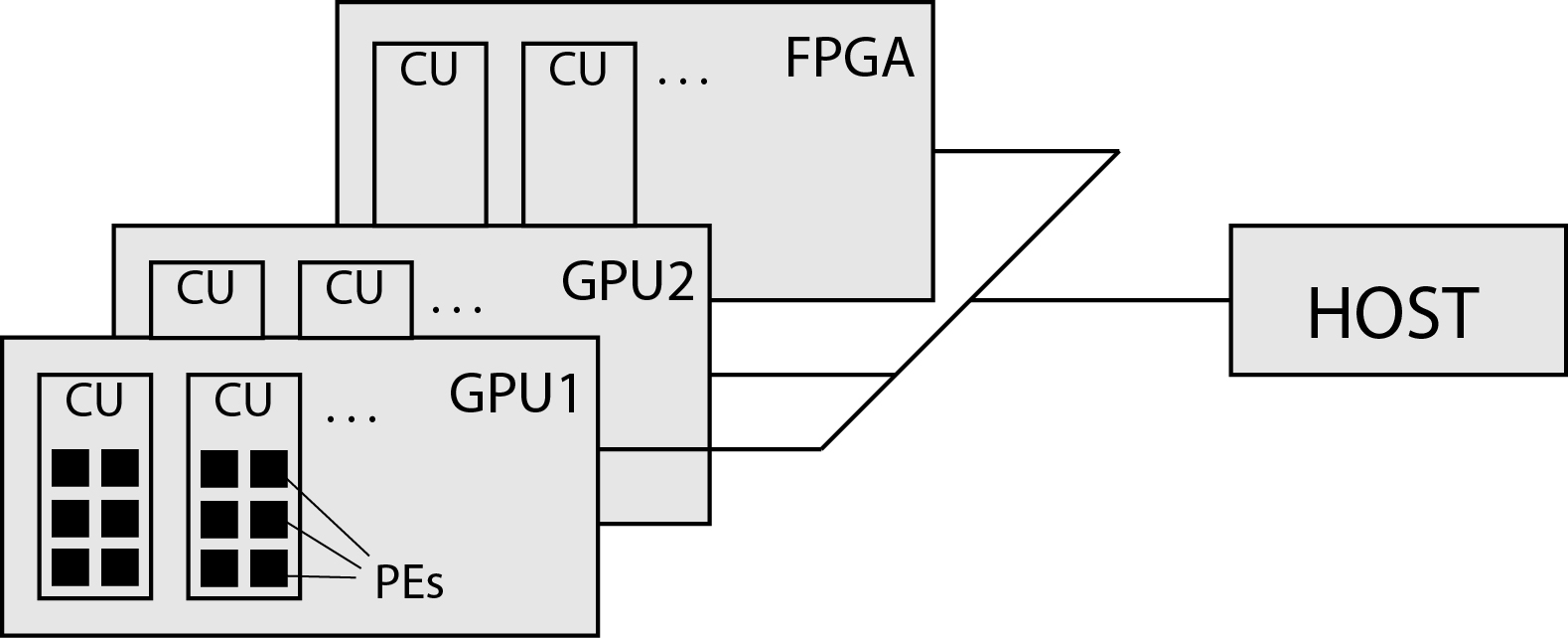
void vectorAdd( float *vecA, float *vecB, float *vecC ) {
int tid = 0;
while (tid < 128) {
vecC[tid] = vecA[tid] + vecB[tid];
tid += 1;
}
}

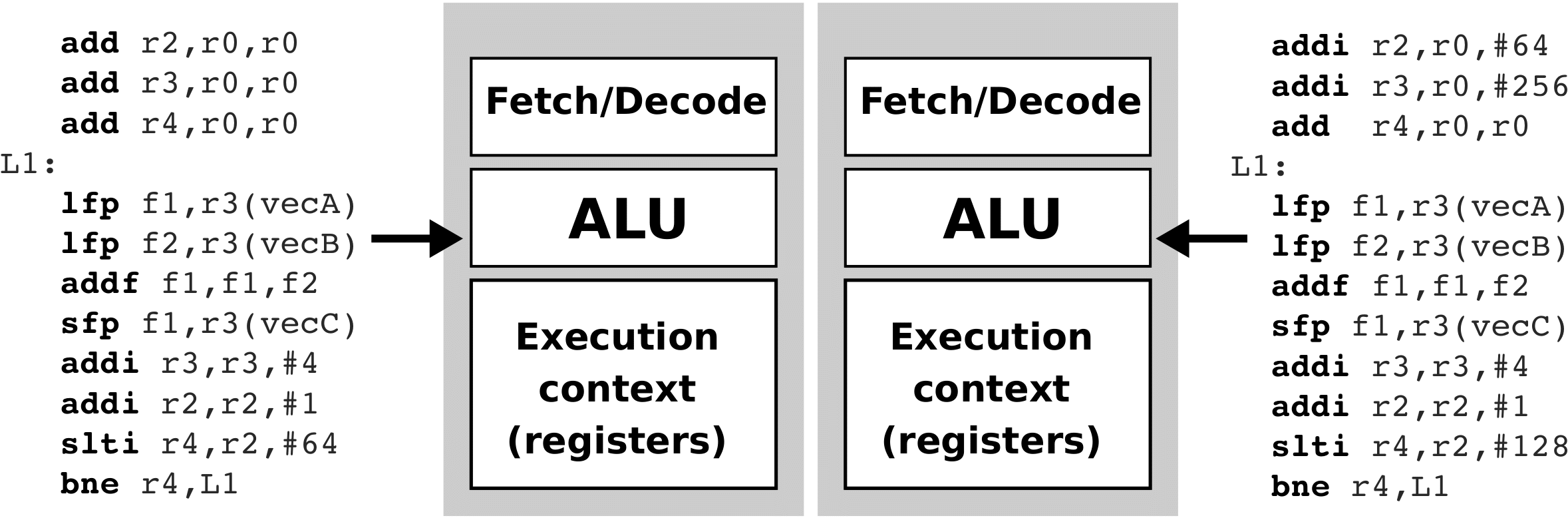
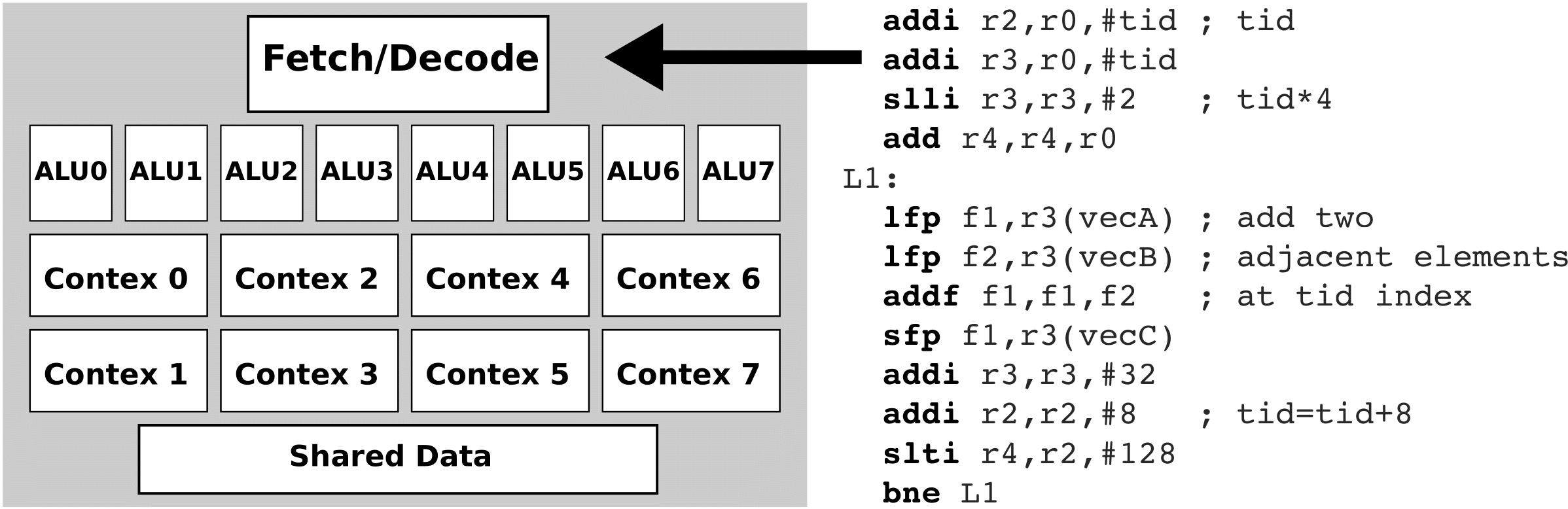
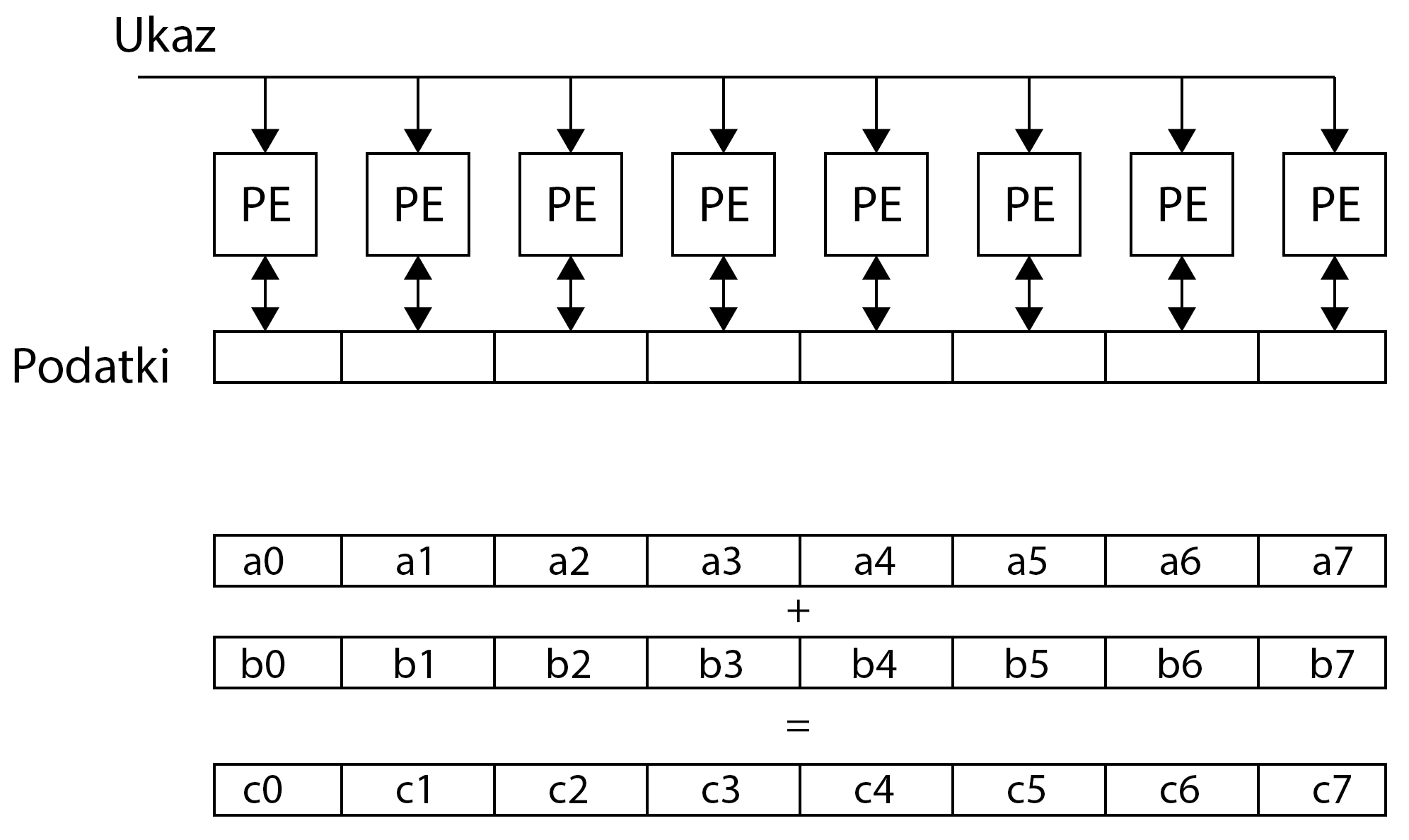

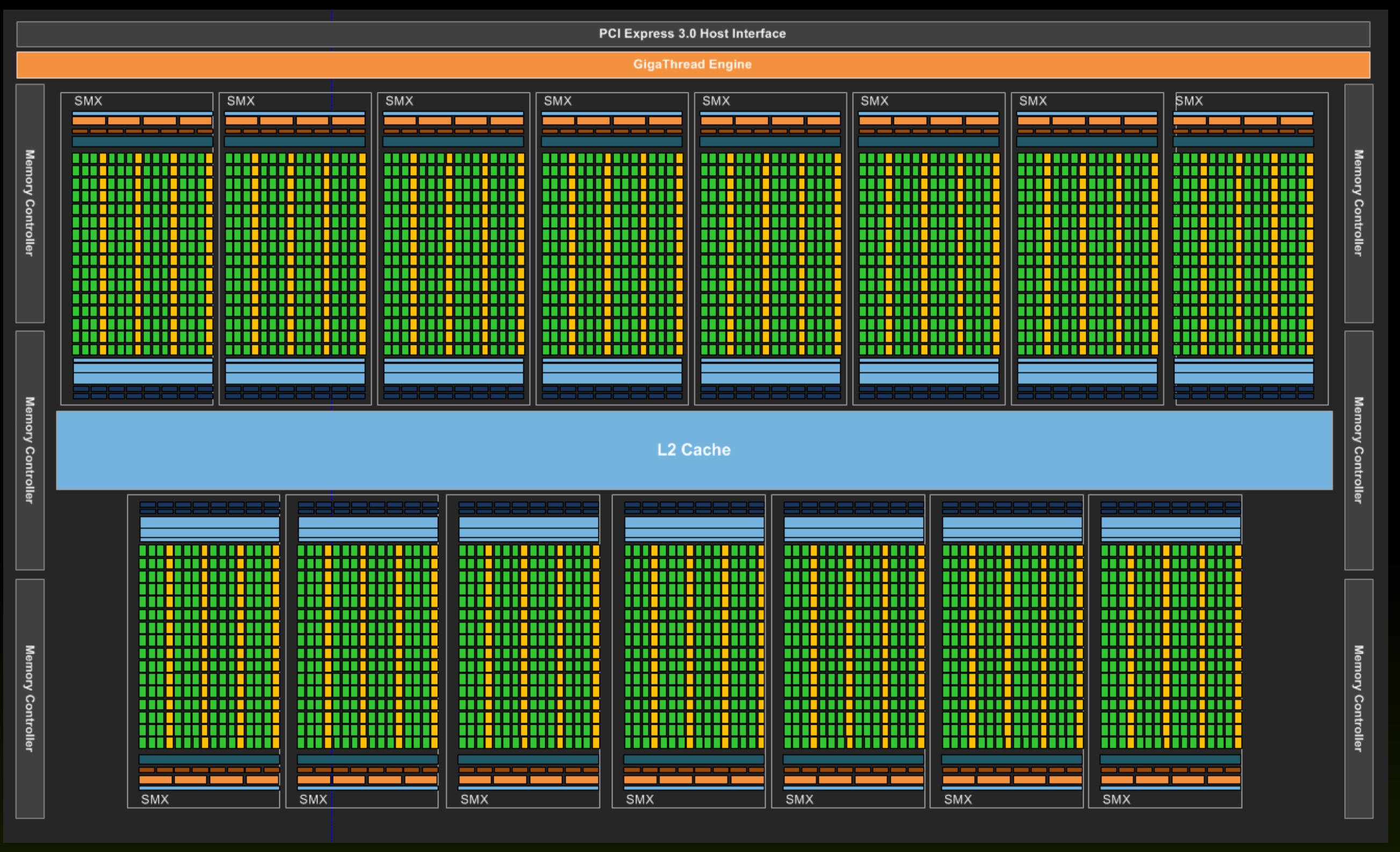
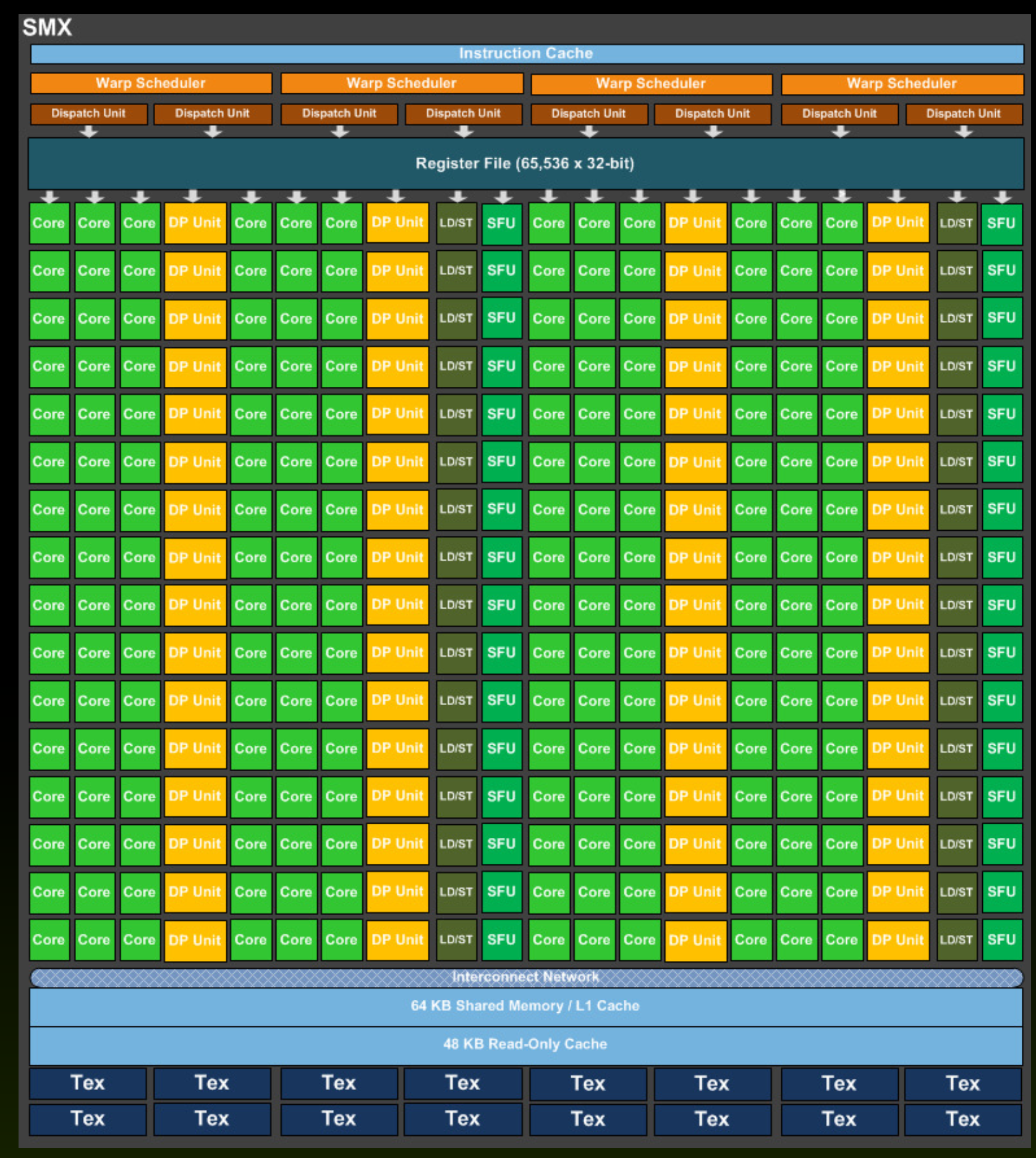
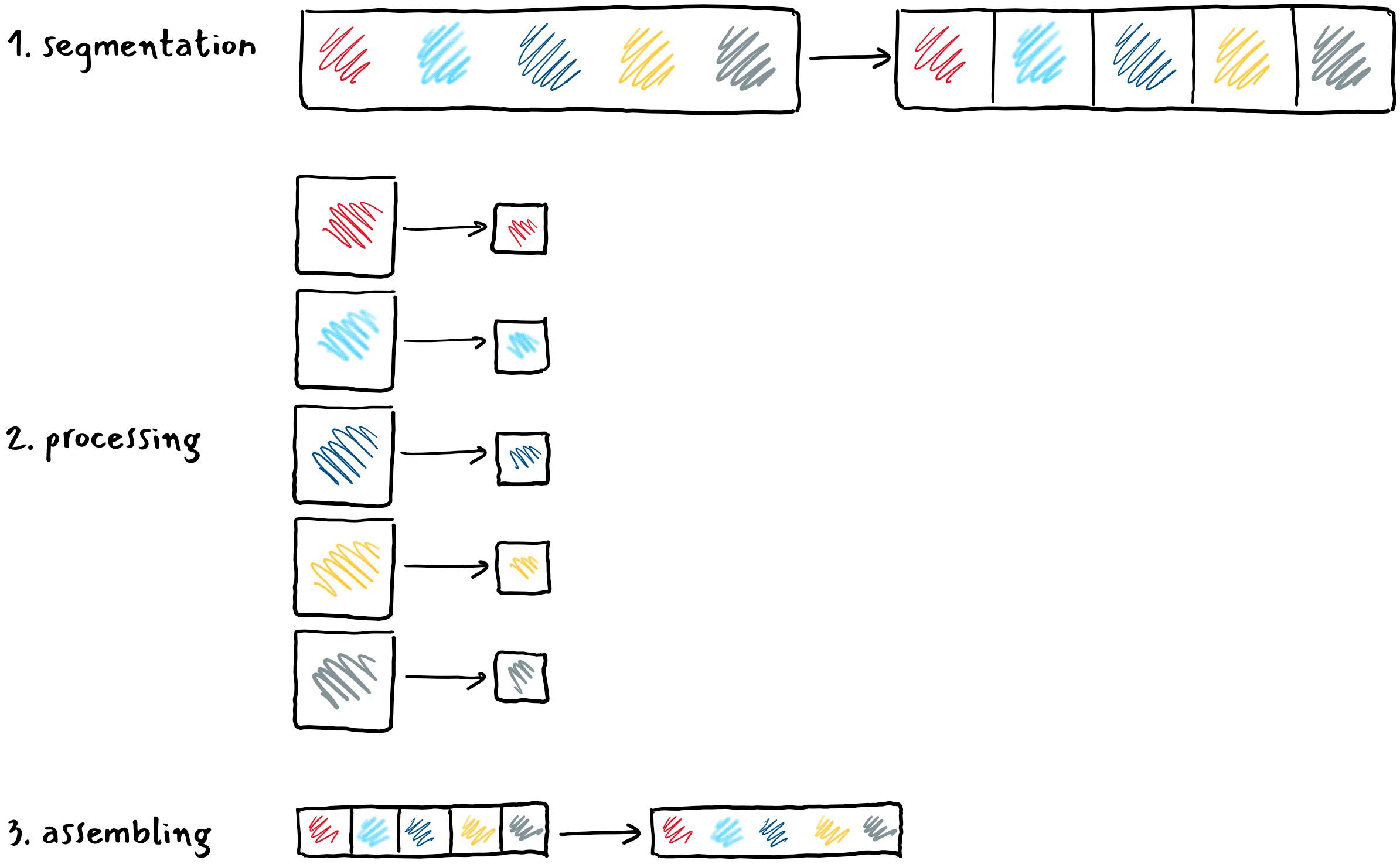
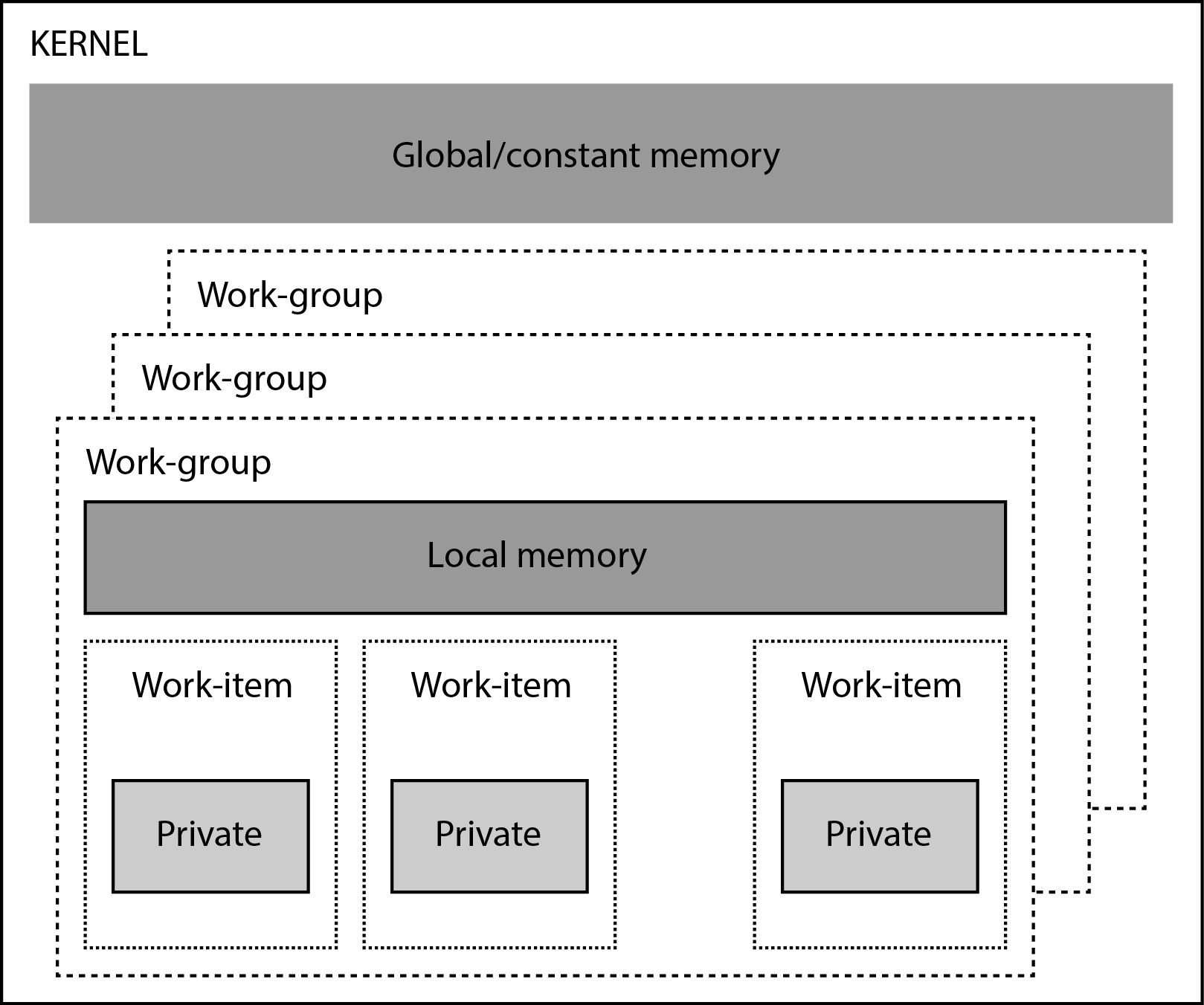
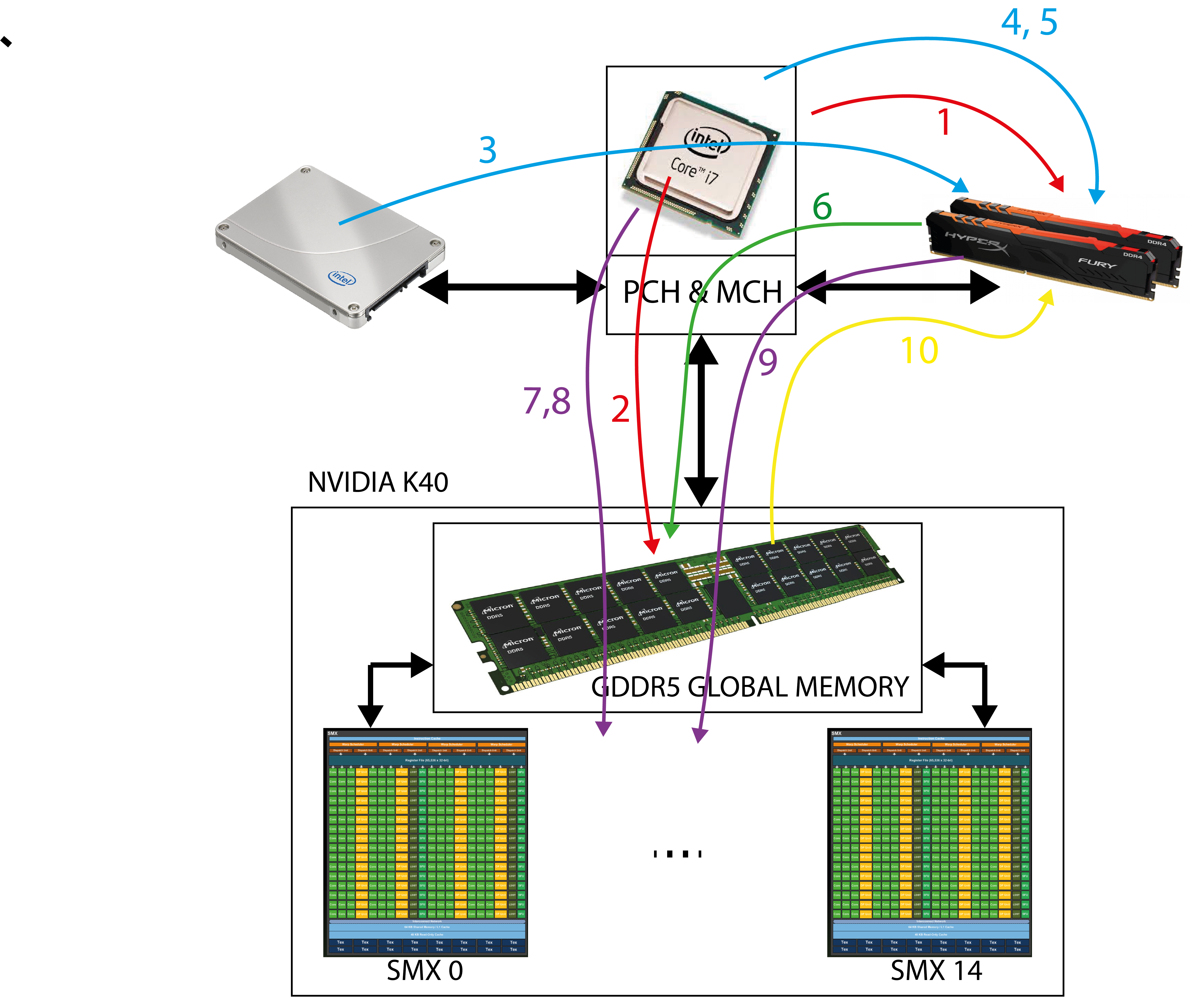
Graphical process units with a large number of process elements are ideal for accelerating problems that are data parallel. These are problems in which the same operation is performed on a large number of different data. Typical data parallel problems are computing with large vectors / matrices or images, where the same operation is performed on thousands or even millions of data simultaneously. If we want to take advantage of such massive parallelism offered to us by GPUs, we need to divide our programs into thousands of threads. As a rule, a thread on a GPU performs a sequence of operations on a particular data (for example, one element of the matrix), and this sequence of operations is usually independent of the same operations that other threads perform on other data. The program written in this way can be transferred to the GPU, where the internal sorters will arrange for sorting threads by compute units (CU) and process elements (PE). The English term for thread in the terminology used in OpenCL is work-item.
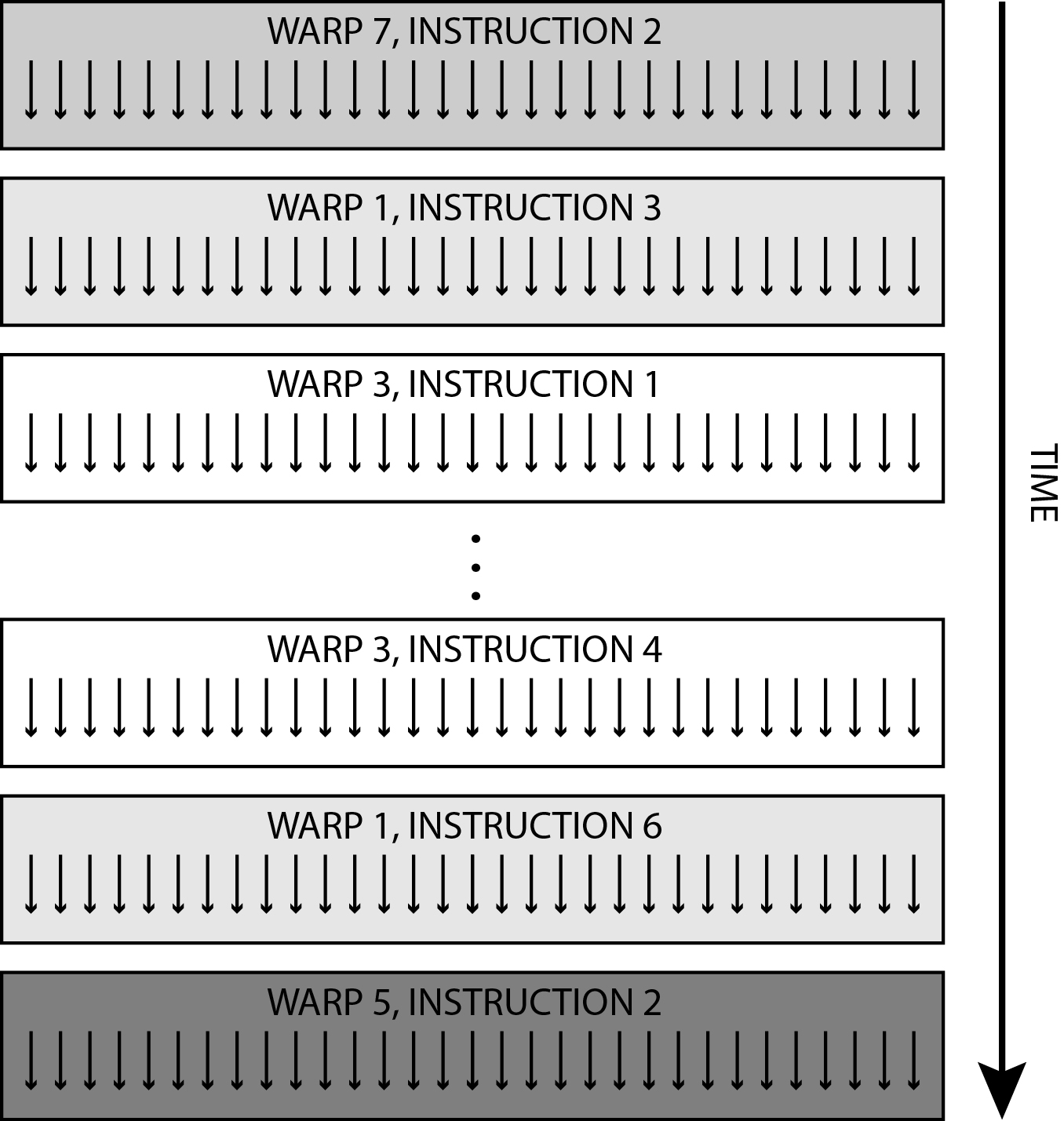
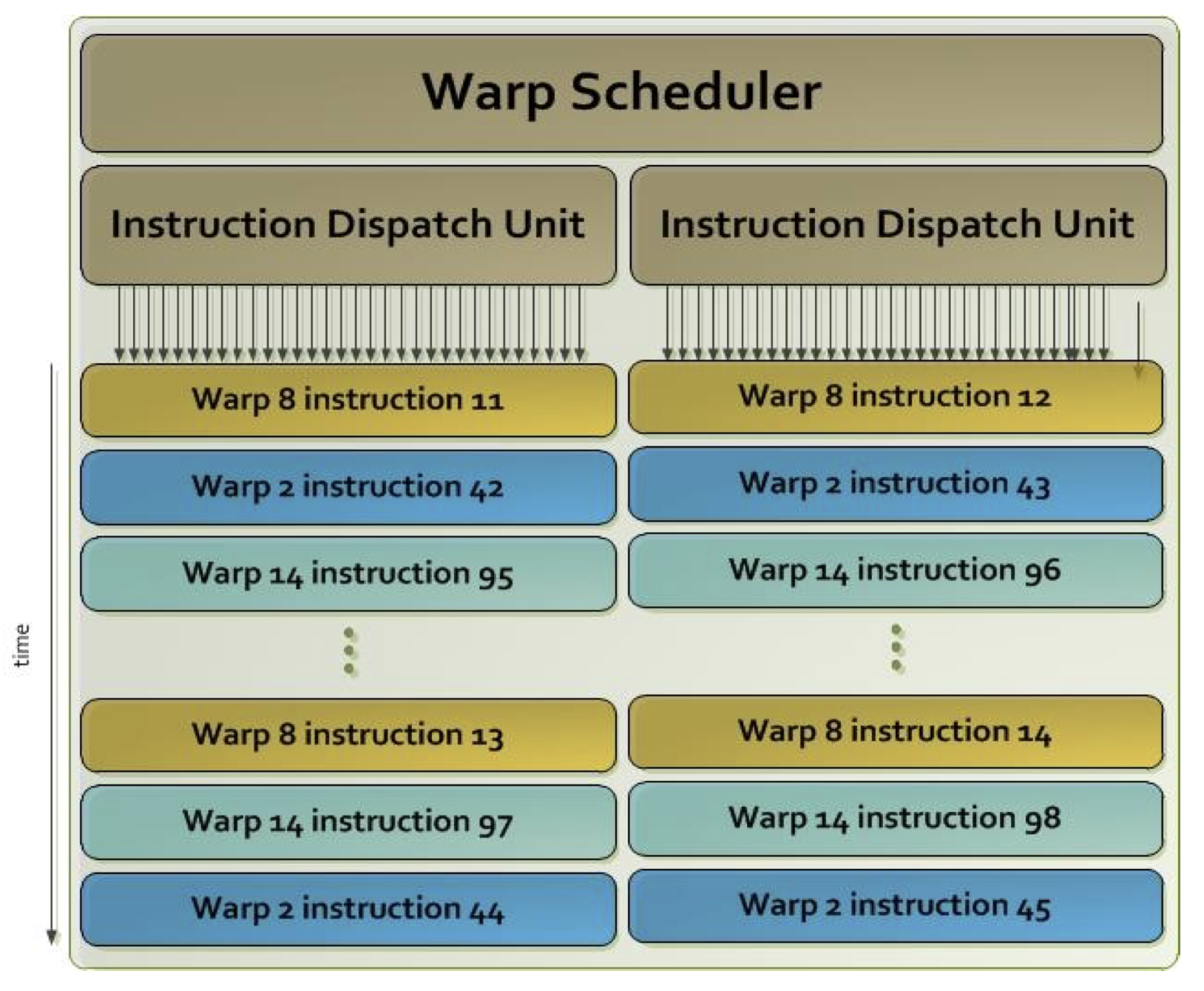
Threads are sorted on GPU in two steps:
| Limitations in Tesla K40 | |
|---|---|
| Number of threads in the bundle |
32 |
| Maximum number of beams in the calculation unit |
64 |
| Maximum number of threads in the calculation unit | 2048 |
| Maximum number of threads in group | 1024 |
| Maximum number of working groups in the calculation unit |
16 |
| Maximum number of registers per thread |
255 |
| The maximum size of local memory in the calculation unit |
48 kB |
GPUs contain various memories that are accessed by individual process elements or individual threads. The image below shows the memory hierarchy on the GPU.
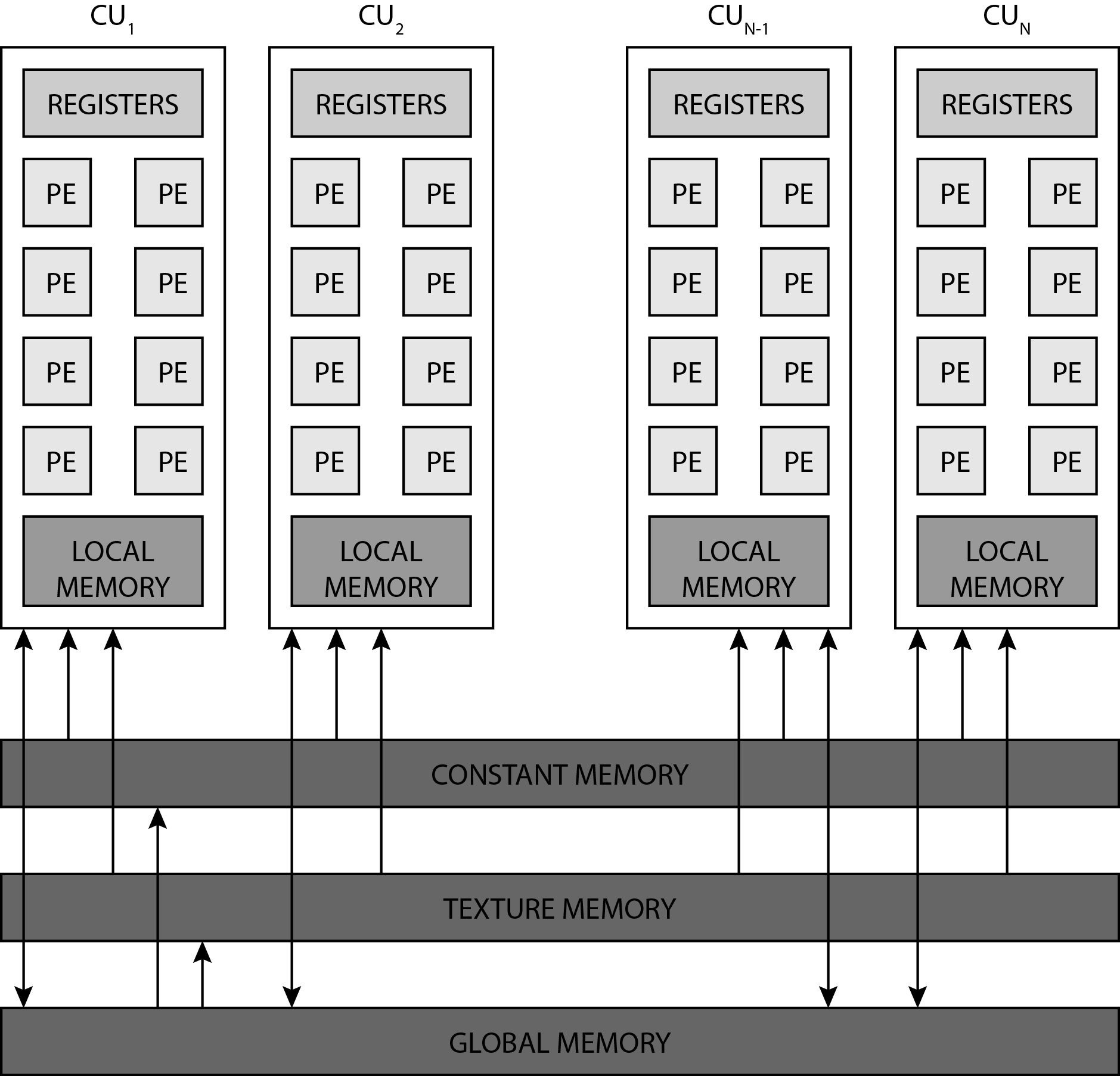
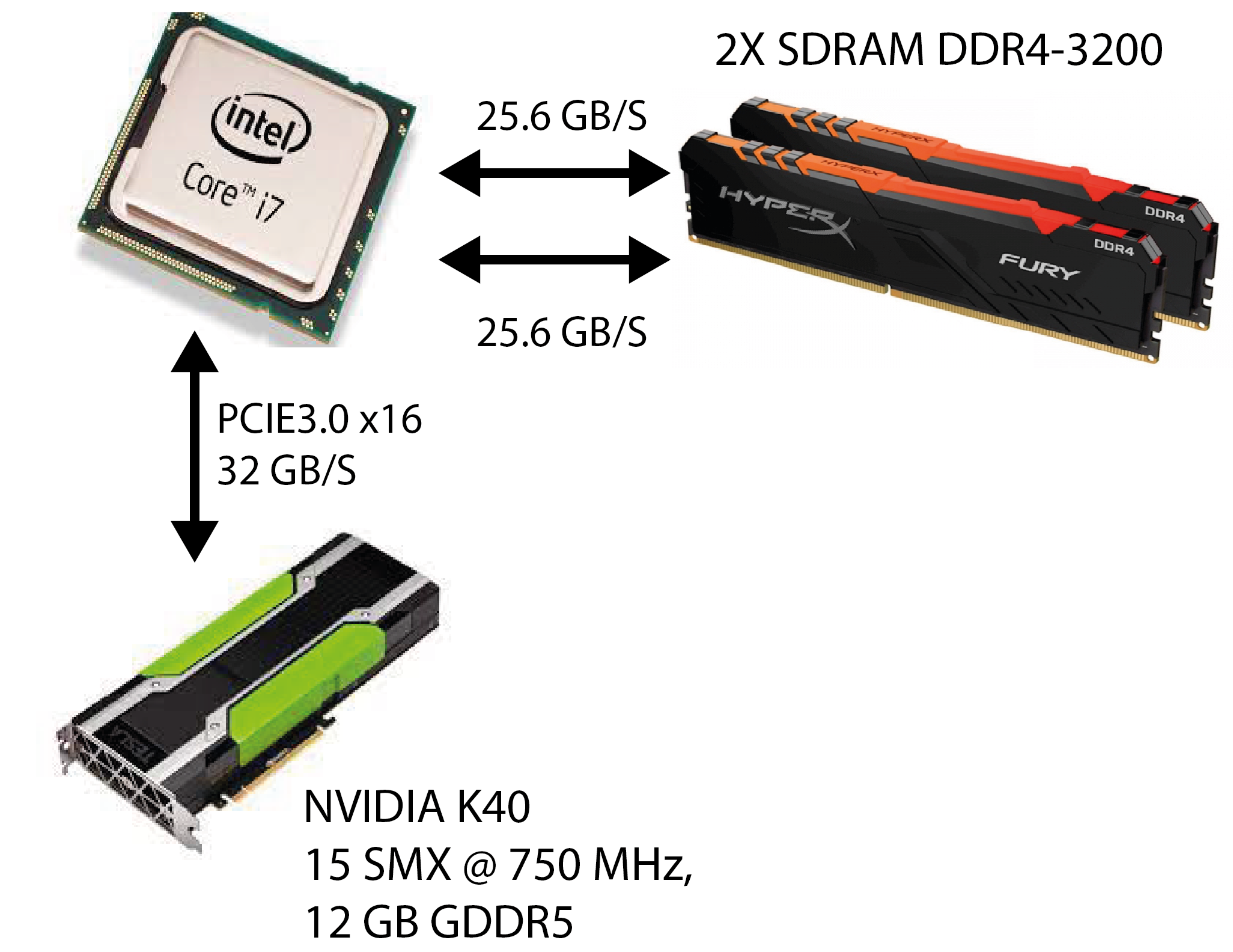
Each compute unit (CU) contains several thousand registers, which are evenly distributed among the individual threads. The registers are private for each thread. The compute unit in the Tesla K40 has 65,536 registers and each thread can use a maximum of 255 registers. Threads keep the most frequently accessed operands in the registers. Suppose we have 120 working groups with 128 threads each. On the Tesla K40 with 15 calculation units, we will have eight working groups per calculation unit (120/15 = 8), with each thread receiving up to 64 registers (65536 / (8 * 128) = 64).
Each compute unit has a small and fast SRAM (static RAM) memory, which is usually automatically divided into two parts during program startup:
With the Tesla K40 accelerator, this memory is 64kB in size and can be shared in three different ways:
As a rule, local memory is used for communication between threads within the same compute uint (threads exchange data with the help of local memory).
It is the largest memory porter on the GPU and is common to all threads and all compute units. The Tesla K40 is implemented in GDDR5. Like all dynamic memories, it has a very large access time (some 100 hour period). Access to main memory on the GPU is always performed in larger blocks or segments - with the Tesla K40 it is 128 bytes. Why segment access? Because the GPU forces the threads in the item bundle to simultaneously access data in global memory. Such access forces us into data parallel programming and has important implications. If threads in a bundle access adjacent 8-, 16-, 24-, or 32-bit data in global memory, then that data is delivered to the threads in a single memory transaction because they form a single segment. However, if only one thread from the bundle accesses a data in global memory (for example, due to branches), access is performed to the entire segment, but unnecessary data is discarded. However, if two threads from the same bundle access data belonging to two different segments, then two memory accesses are required. It is very important that when threading our programs, we ensure that memory access is grouped into segments (memory coalescing) - we try to ensure that all threads in the bundle access sequential data in memory.
Constant and texture memories are just separate areas in global memory where we store constant data, but they have additional properties that allow easier access to data in these two areas: - constant data in constant memory is always cached, this memory allows sending a single data to all threads in the bundle at once (broadcasting), - constant data (actually images) in the texture memory is always cached in the cache, which is optimized for 2D access; this speeds up access to textures and constant images in global memory.
So far, we have learned how the GPU is built, what the compute units and process elements are, how the programs run on it, how the workgroups and threads are arranged, and what the GPU memory hierarchy is. Now is the time to look at what the software model is.
OpenCL (Open Computing Language) is an open source framework designed for parallel programming of a wide range of heterogeneous systems. OpenCL contains the OpenCL C programming language, designed to write program code that will run on devices (such as GPU or FPGA). We have learned before that we call such programs kernels. The same kernel executes all threads on the GPU. Unfortunately, OpenCL has one major drawback: it is not easy to learn. Therefore, before we can write our first program in OpenCL, we need to learn some important concepts.
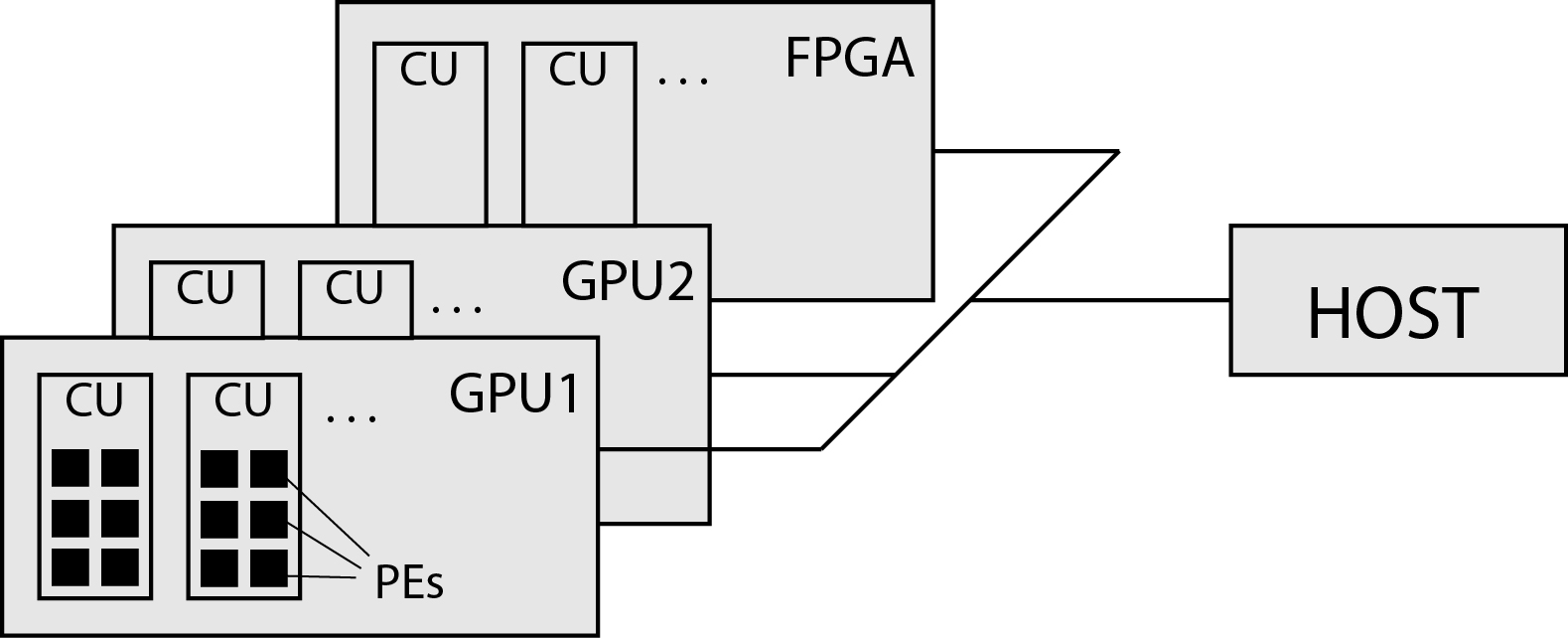
OpenCL sees a general heterogeneous system as a platform consisting of a host and one or more different devices. Devices are usually GPU or FPGA accelerators. The platform is shown in the image below.
Each program in OpenCL consists of two main parts:
Let’s start with a simple example of adding two vectors. We will solve the problem in two ways. First, we’ll start out quite naively and focus only on the basics of GPU programming and the steps on the host that are needed to run our first program
on GPU. In the second mode, we will then focus on the kernel improvement implemented on the GPU.
The code below shows the implementation of a function in C for summing two vectors whose elements are real numbers, represented by floating-point
notation with single precision (float).
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | |
1 2 3 4 5 6 7 8 9 10 11 12 | |
We must be aware that only now, ie during the execution of the program on the host, the kernel, which we read from the kernel.cl file, is translated. Any errors in the code in kernel.cl will only appear now, during translation, and not when compiling the host program. Therefore, in the event of translation errors (for the clBuildProgram() function), they must be stored in a data set in main memory and displayed if necessary. This can be done with the clGetProgramBuildInfo() function:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | |
The clGetProgramBuildInfo() function is called twice. First, to determine the length of the error message, and second, to read the entire error message. The following is an example of an error printout in the case where we used an undeclared name for vector B in a kernel:
Error: Failed to build program executable!
<kernel>:9:35: error: use of undeclared identifier 'vecBB'; did you mean 'vecB'?
vecC[myID] = vecA[myID] + vecBB[myID];
^~~~~
vecB
<kernel>:2:33: note: 'vecB' declared here
__global float* vecB,
^
1 2 3 4 5 6 7 8 9 10 11 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
1 2 3 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
The full code from this chapter can be found in the 02-vector-add-short folder here.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
After completing the kernel, the host must read the product vector from the device and add all its elements in a loop:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
|
The full code from this chapter can be found in the 05-dot-product-naive folder here.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
In our case, we will have 64 threads in one working group. First, in line 5, we declare the field in which each thread in the working group will store the sum of its products:
5 |
|
9 10 11 12 |
|
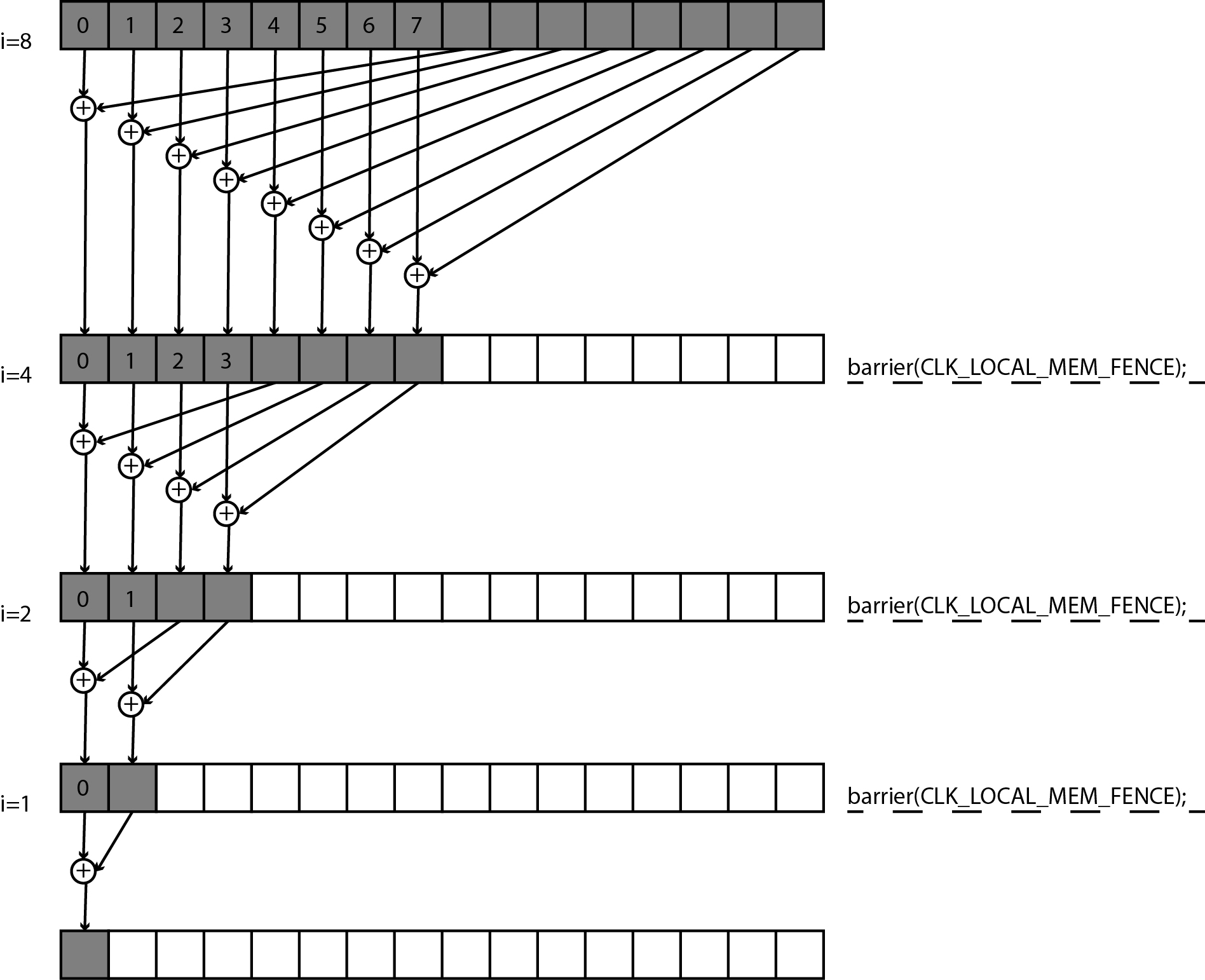
We will use a procedure called reduction to add the elements. Suppose we have only 16 elements to add up and 16 threads in a working group. In the first step, each of the first eight threads in the workgroup will add an element with its myLID index and an element with its myLID + 8 index and write the sum in an element with its myLID index. The remaining eight threads in the working group will not do anything. Then all the threads will wait at the obstacle. In the next step, only each of the first four threads will add an element with its myLID index and an element with its myLID + 4 index, the other threads will not add up. Before continuing with the work, all the threads will again wait in front of the obstacle. Thus, we will continue the process until there is only one thread with index 0 left, which will add up the element with index 0 and the element with index 1. The reduction procedure just described is shown by the code below in lines 24 to 34.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
|
36 37 38 39 |
|
The program on the host this time requires minor changes. The partial results that we will read from the device will now be contained in the vecC_d field, which will have only as many elements as there are workgroups:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
The full code from this chapter can be found in the 06-dot-product-reduction folder here.
1 2 3 4 5 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
1 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
The full code from this chapter can be found in the 07-dot-product-profiling folder here.
We are now tackling a problem that will help us understand the 2-dimensional space of the NDRange and the use of local memory to speed up kernel implementations on GPU devices. For this purpose, we will program the multiplication of matrices. Without
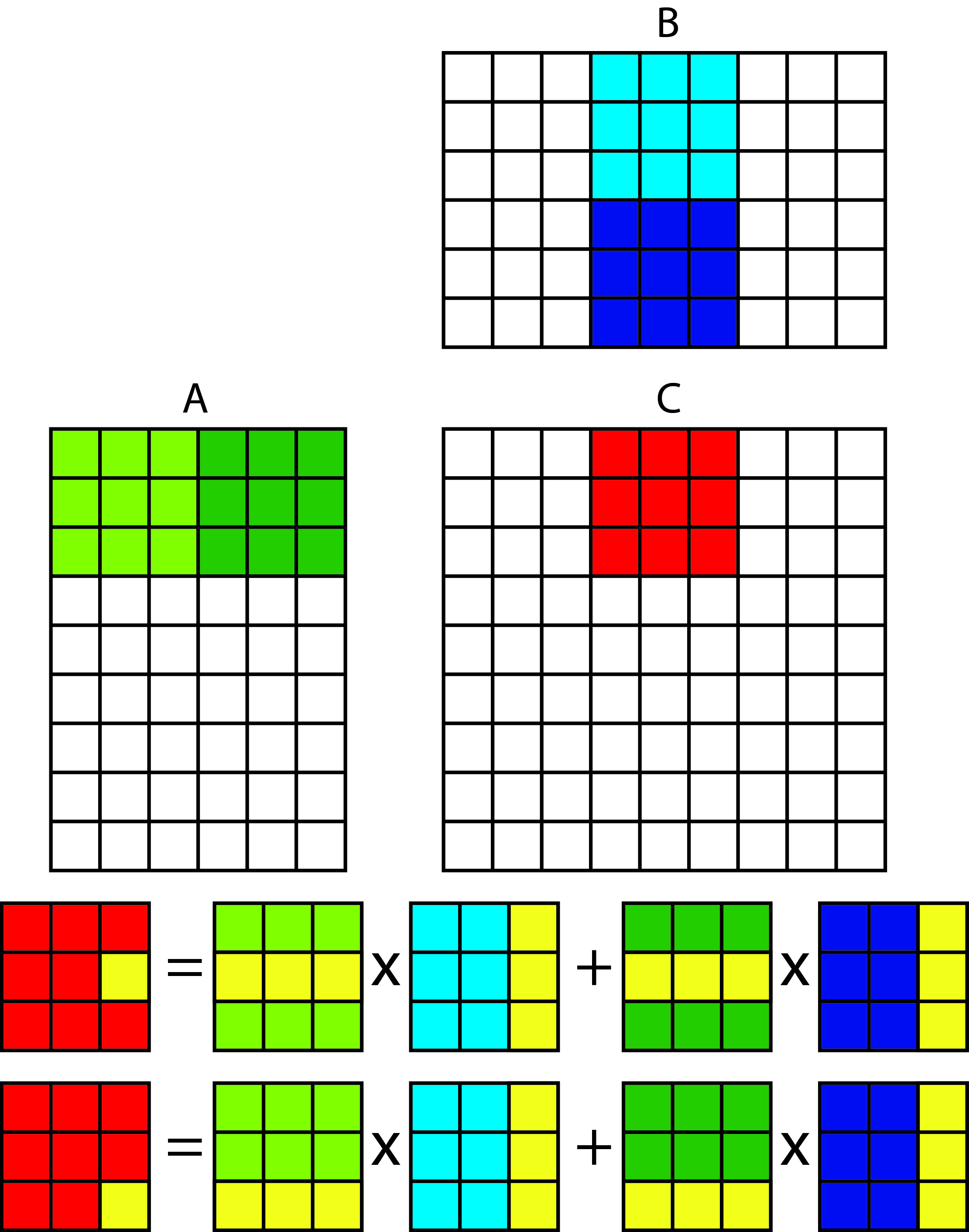
loss of generality, we will confine ourselves to square matrices of size NxN. The multiplication of the square matrices A and B is shown in the figure below:

The element of the matrix C [i, j] is obtained by scalarly multiplying the i-th row of the matrix A and the j-th column of the matrix B. So, for each element of the matrix C we have to calculate one scalar product between the row from A and the column from B. the figure shows which rows and columns need to be scalarly multiplied by each other to obtain the elements C [1,2], C [5,2] and C [5,7]. For example, for C [5,7] we need to scalarly multiply the 5th row from matrix A and the 7th column from matrix B.
With a simple version of matrix multiplication, we will first learn about the use of two-dimensional NDRange spaces.
This time, we’re not going to deal with the effectiveness of a kernel yet. We will prepare it so that each thread it will perform will calculate only one element of the product matrix.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
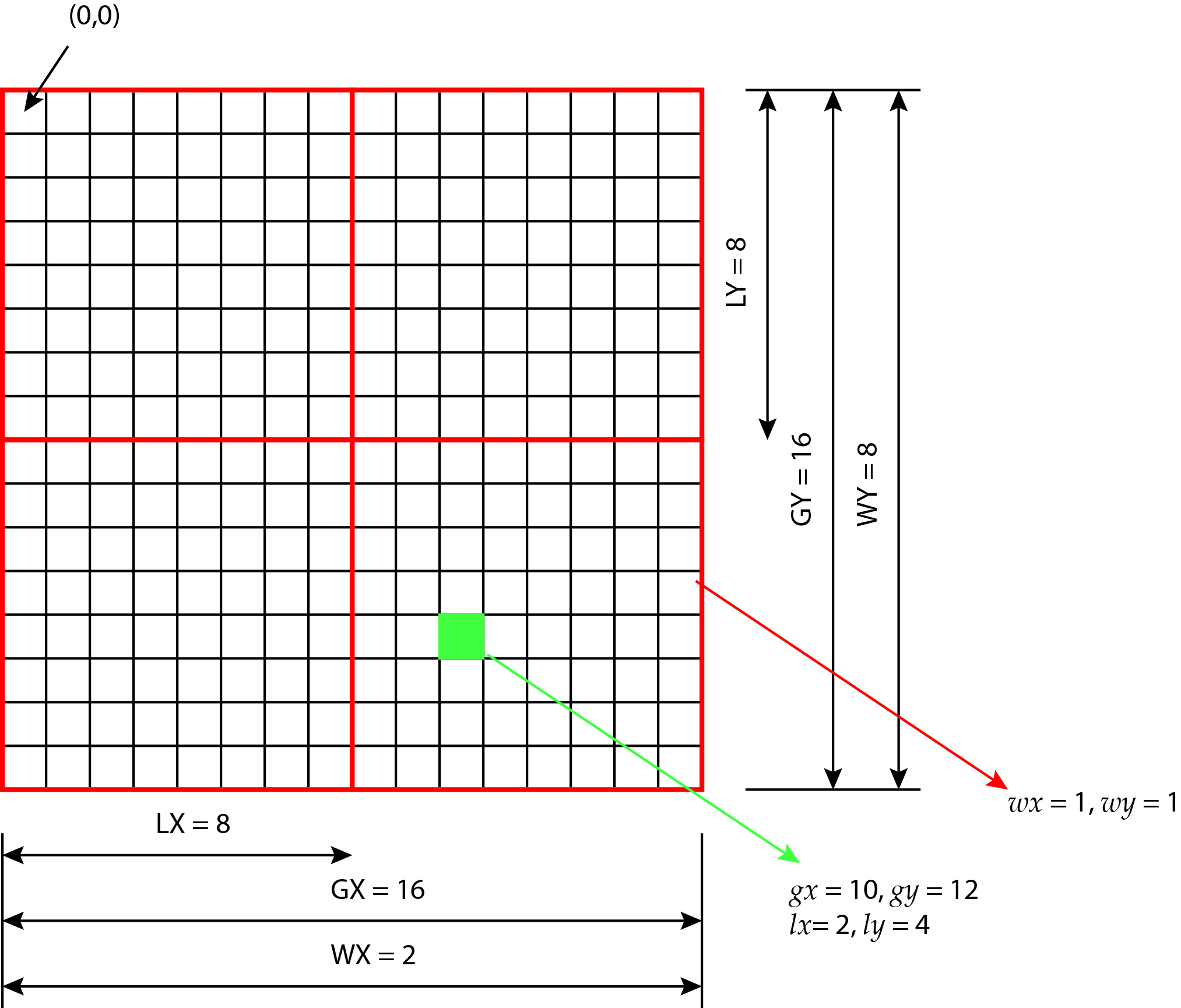
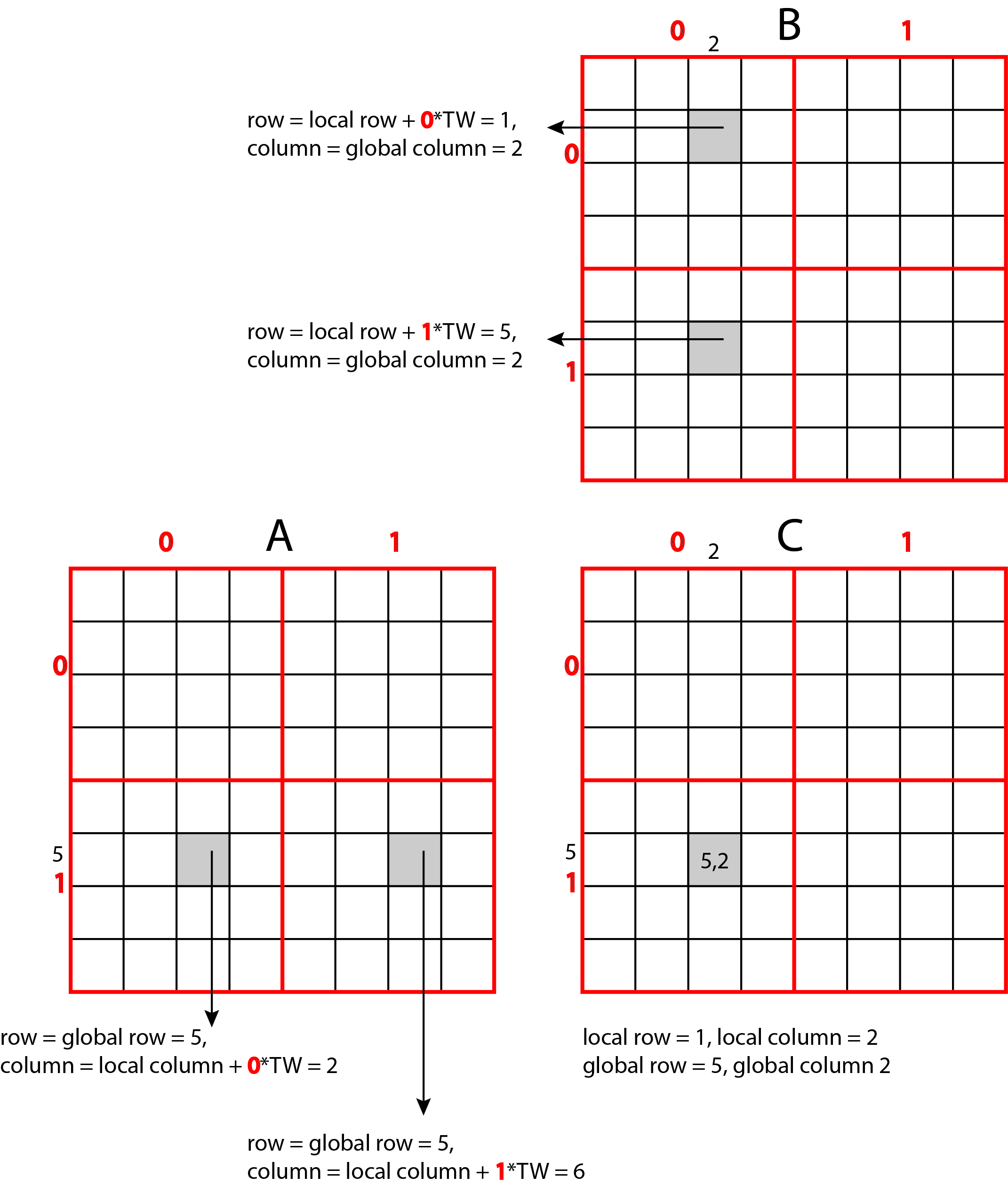
Since the elements of the matrices are organized in a 2-dimensional field, it is most natural that we also organize the threads into a two-dimensional space NDRange. Each thread will now be defined by a pair of global indexes (i, j). In the above code, therefore, each thread first obtains its global index by calling the get_global_id function (lines 8 and 9).
8 9 | |
20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | |
In addition, the program on the host must set the global size of the NDRange space and the number of threads in the workgroup.
1 2 | |
1 2 3 4 5 6 7 8 9 10 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | |
Each thread in the for loop walks through all the tiles needed to calculate its element of the matrix C (lines 23 to 38).
23 24 25 | |
In each iteration, the for loops of the threads from the same workgroup first transfer the tiles from matrix A and matrix B to the local memory and wait at the obstacle (lines 24 to 31).
24 25 26 27 28 29 30 31 32 | |
| Input image |
Output image |
|---|---|
 |
 |
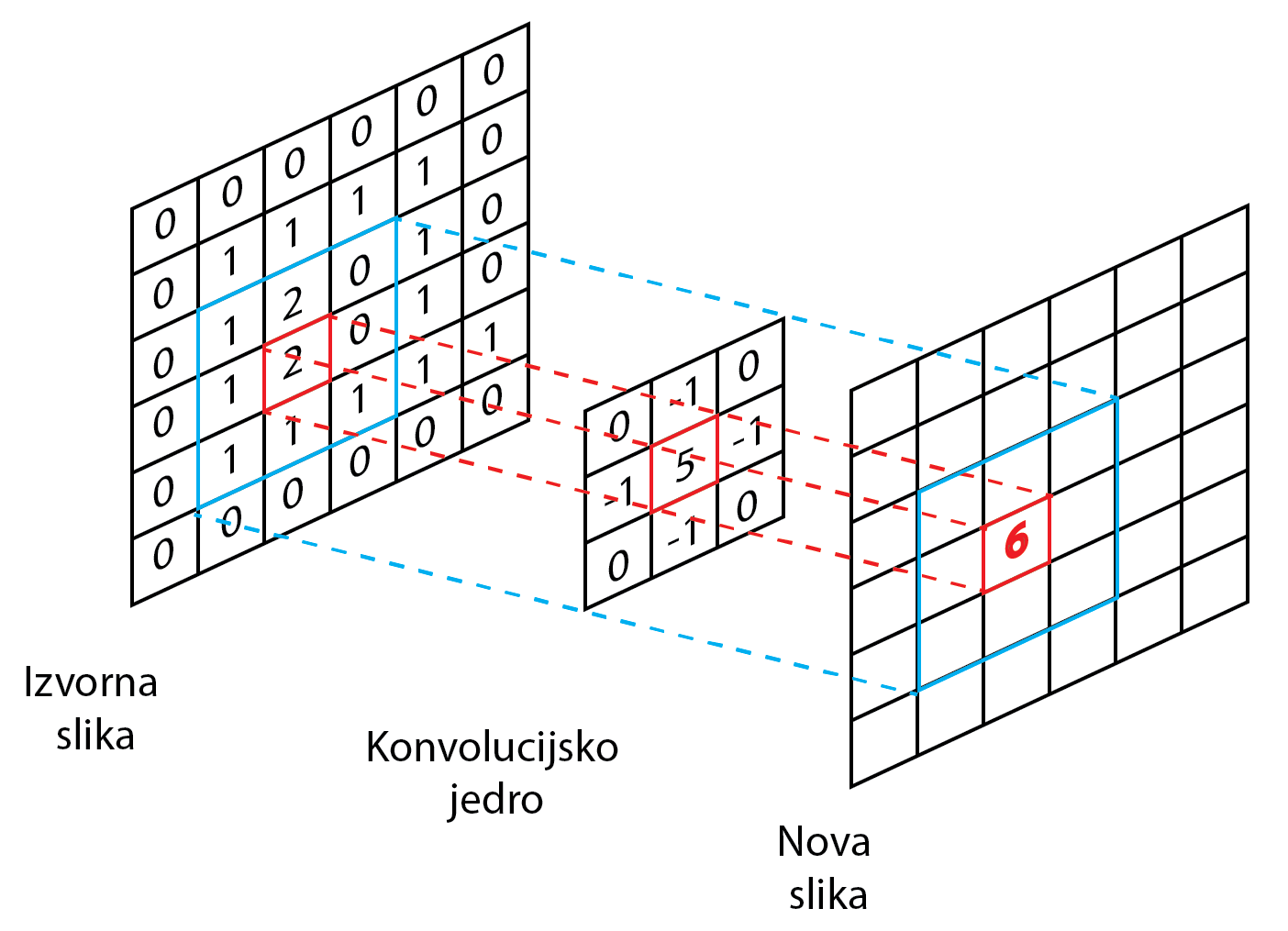
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | |
In the for loop, we walk across all the channels and for each channel separately, the thread reads the values of five pixels from the image: the pixel for which it calculates the new value, and its four neighbors (left, right, top and bottom), as required by the Laplace core . To access the values of individual pixels, prepare the getIntensity function:
1 2 3 4 5 6 7 8 9 10 11 12 | |
1 2 3 4 5 | |
[patriciob@nsc-login 09-image-filter]$ srun prog sharpenGPU celada_in.png celada_out.png
Loaded image celada_in.png of size 2580x1319.
Program size = 5894 B
Kernel Execution time is: 1.388 milliseconds
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
1 2 3 4 5 6 7 8 9 | |
The openCL function convert_short4 performs an explicit conversion from the uchar4 vector to the short4 vector. This time, a kernel of sharpenGPU_vecotor on the Nvidia Tesla K40 GPE is performed in 0.66 milliseconds when processing an image of 2580x1319 pixels:
[patriciob@nsc-login 09-image-filter]$ srun prog sharpenGPU_vector celada_in.png celada_out.png
Loaded image celada_in.png of size 2580x1319.
Program size = 5894 B
Kernel Execution time is: 0.662 milliseconds
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | |
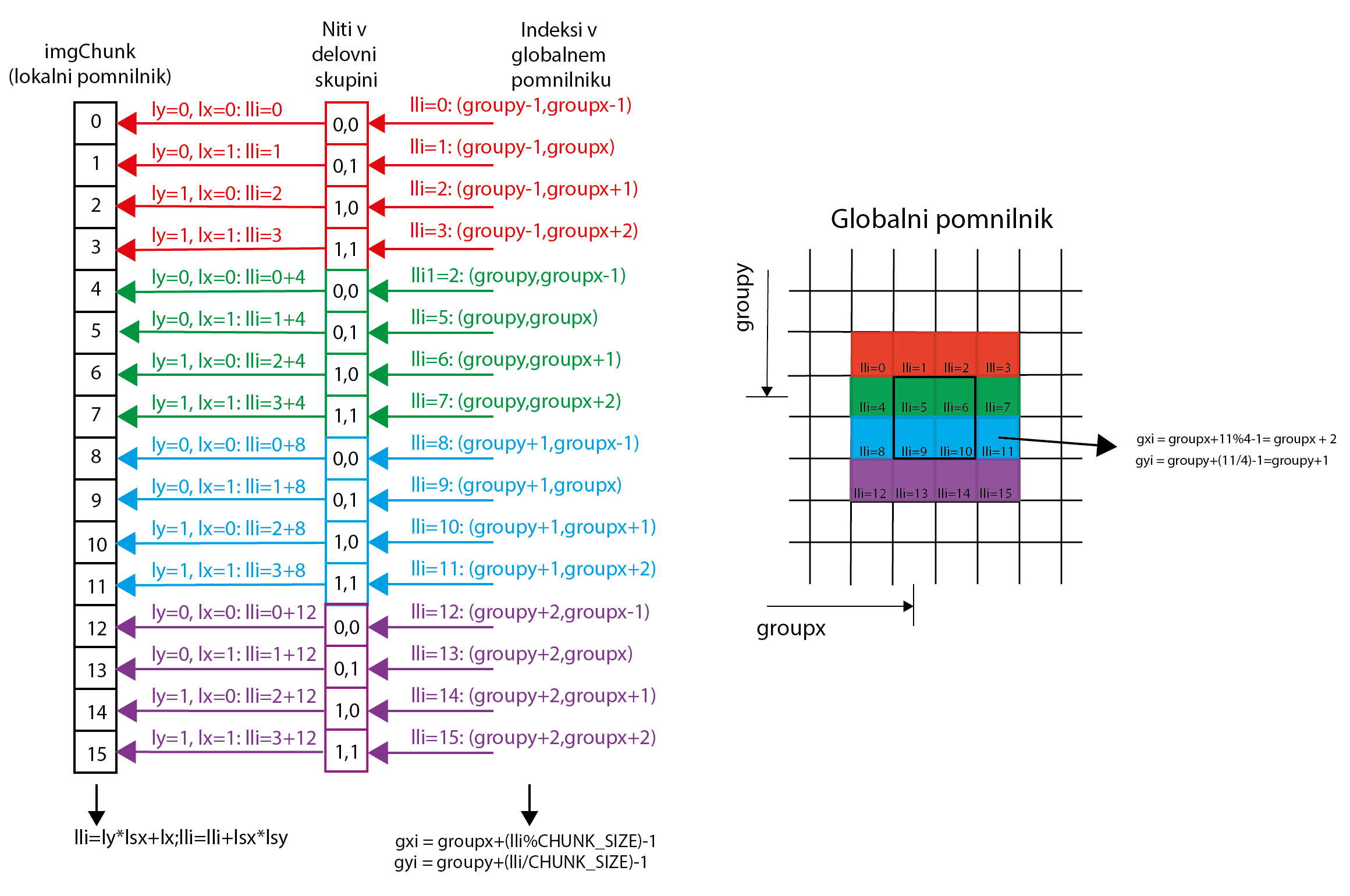
To have access to consecutive words in global memory, for one block of thread we always calculate all the linearized indices (lli) of the elements in imgChunk that the individual threads in the block carry. These linearized indexes are also used to determine the global memory elements that each thread transmits (picture on the right) with the following code:
25 26 27 | |
34 35 36 37 38 39 40 41 42 43 44 45 46 47 | |
This time kernel of sharpenGPU_local_vector on the Nvidia Tesla K40 GPE is performed in 0.56 milliseconds when processing a 2580x1319 pixel image:
[patriciob@nsc-login 09-image-filter]$ srun prog sharpenGPU_local_vector_linear celada_in.png celada_out.png
Loaded image celada_in.png of size 2580x1319.
Program size = 7000 B
Kernel Execution time is: 0.557 milliseconds
We see that the use of local memory brings us additional performance speed, as each image element is read only once from the global memory (except for image elements at the edges, which are read twice). Compared to the naive version of the kernel, the acceleration is 2.5 times! The latter finding should not surprise us, as we know that the bottleneck in computers is actually DRAM memory, and by considering the organization of data in DRAM memory, how to access DRAM memory, and caching (since local memory is a software-controlled cache), we can significantly influence time implementation of the programs.
The full code from this chapter can be found in the 09-image-filter folder here.

