OpenCL
So far, we have learned how the GPU is built, what the compute units and process elements are, how the programs run on it, how the workgroups and threads are arranged, and what the GPU memory hierarchy is. Now is the time to look at what the software model is.
OpenCL framework
OpenCL (Open Computing Language) is an open source framework designed for parallel programming of a wide range of heterogeneous systems. OpenCL contains the OpenCL C programming language, designed to write program code that will run on devices (such as GPU or FPGA). We have learned before that we call such programs kernels. The same kernel executes all threads on the GPU. Unfortunately, OpenCL has one major drawback: it is not easy to learn. Therefore, before we can write our first program in OpenCL, we need to learn some important concepts.
Platform and devices
OpenCL sees a general heterogeneous system as a platform consisting of a host and one or more different devices. Devices are usually GPU or FPGA accelerators. The platform is shown in the image below.
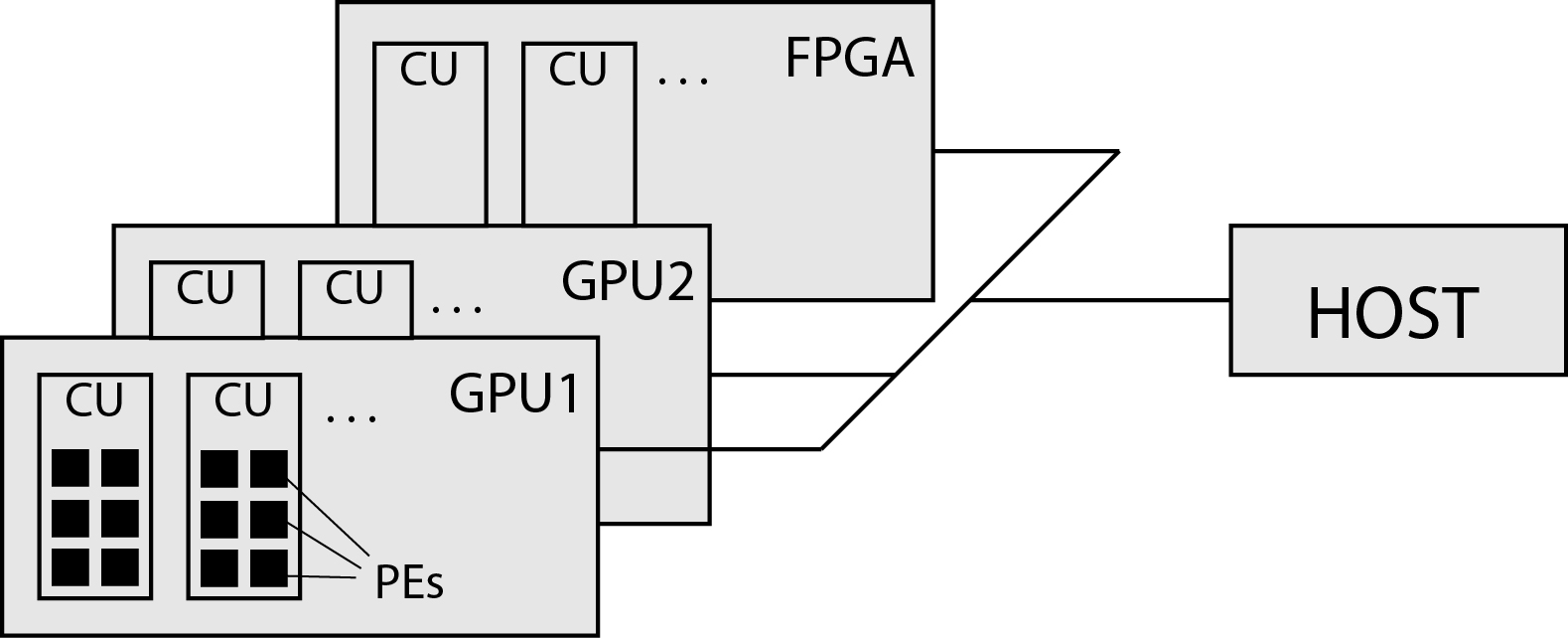
Each program in OpenCL consists of two main parts:
- code running on the host program, and
- one or more kernels running on the device.
OpenCL implementation model
We have already met the GPU implementation model before. We learned about compute units (CU) and process elements (PE) and threads and groups of threads. OpenCL uses a similar abstraction - a kernel executes a large number of threads simultaneously. These are grouped into working groups. Threads in workgroups can share data over local memory and can be synchronized with each other.
Each thread has its own unique identifier (ID). In principle, IDs are neither one-, two-, or three-dimensional, and are given with integers. For the purposes of the most comprehensible explanation, we will limit ourselves to two dimensions below. Thread indexing is always adapted to the spatial organization of the data. For example, if our data is vectors, we will neither index in one dimension, but if our data is a matrix or image, we will not index in two dimensions. Thus, OpenCL allows us to spatially organize threads in the same way as data. For example, in the case of images, the indexes of the threads will coincide with the indexes (coordinates) of the image points. In OpenCL terminology, we call thread space NDRange. We also index working groups in one-, two- or three-dimensional space. An example of two-dimensional indexing is shown in the figure below.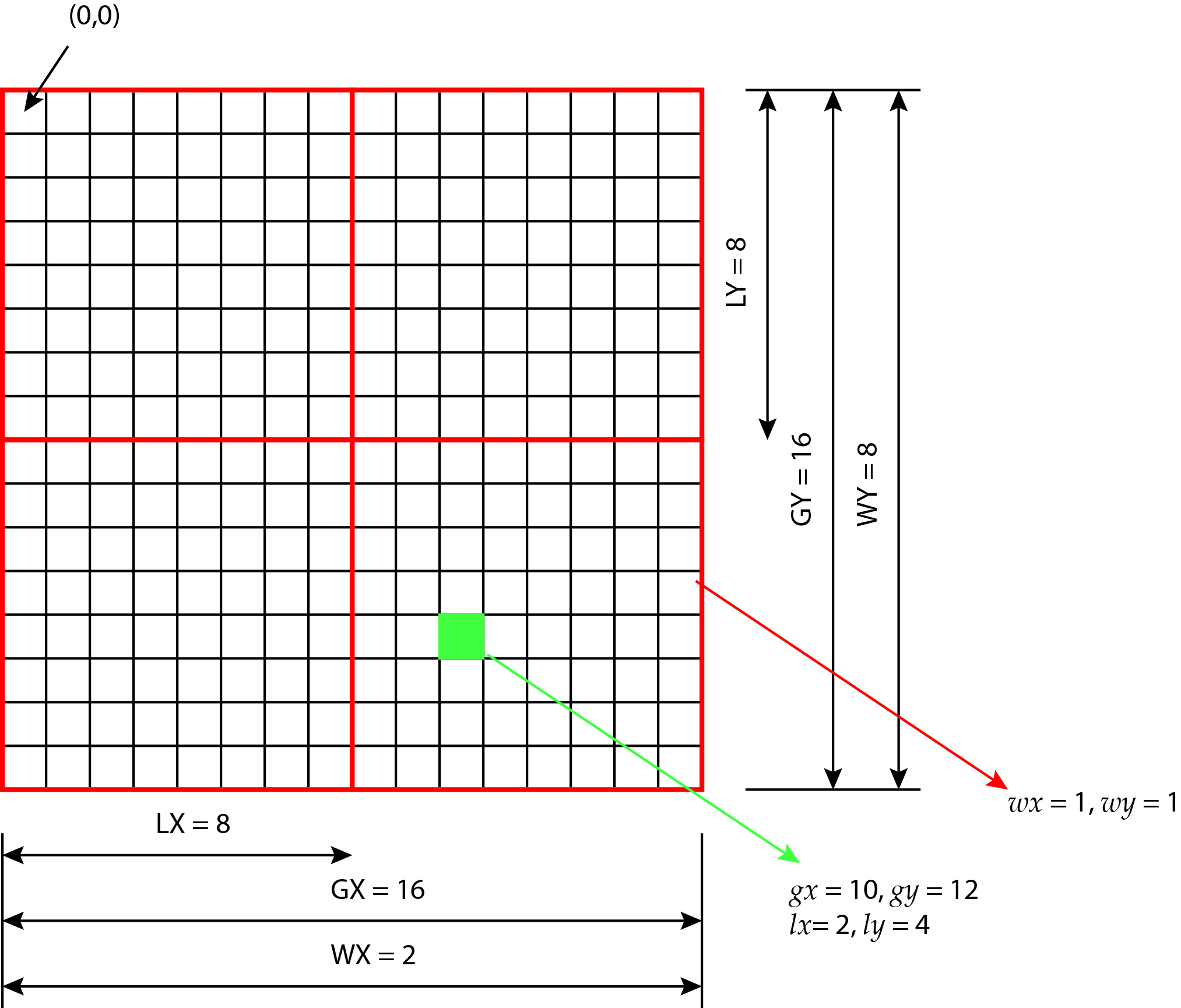
Each thread in the 2D space of the NDRange has two pairs of indexes:
- global index (global ID) and
- local index (local ID).
The global index indicates the index neither in the whole space nor the NDRange, while the local index neither indicates its position within the working group. In the figure above, the NDRange thread space contains 16 x 16 = 256 threads in 4 work groups. Each group, however, has 8x8 = 64 threads. The global index of each thread is determined by a pair (gy, gx), where gy denotes the index in the vertical direction (i.e., row) and gx denotes the index in the horizontal direction (i.e., column). The coordinate (0,0) is always in the upper left corner. Also, the local index of all threads is determined by a pair (ly, lx). For an example, let’s look at a thread marked in green. Its global index is (12.10) while its local index is (4.2). The index of each working group of threads is determined by a pair (wy, wx). Each NDRange thread space has its own dimensions that tell how many threads or groups of threads make it up. The global dimension of the NDRange space in the figure above is determined by a pair (GY, GX) and is (16.16), while the local dimension of an individual group is determined by a pair (LY, LX) and is (8.8). The global dimension of the NDRange thread space can also be measured in thread working groups and is determined by the pair (WY, WX) in the figure above and is (2.2).
OpenCL memory model
OpenCL contains an abstraction of the memory hierarchy on the GPU shown in the figure below.
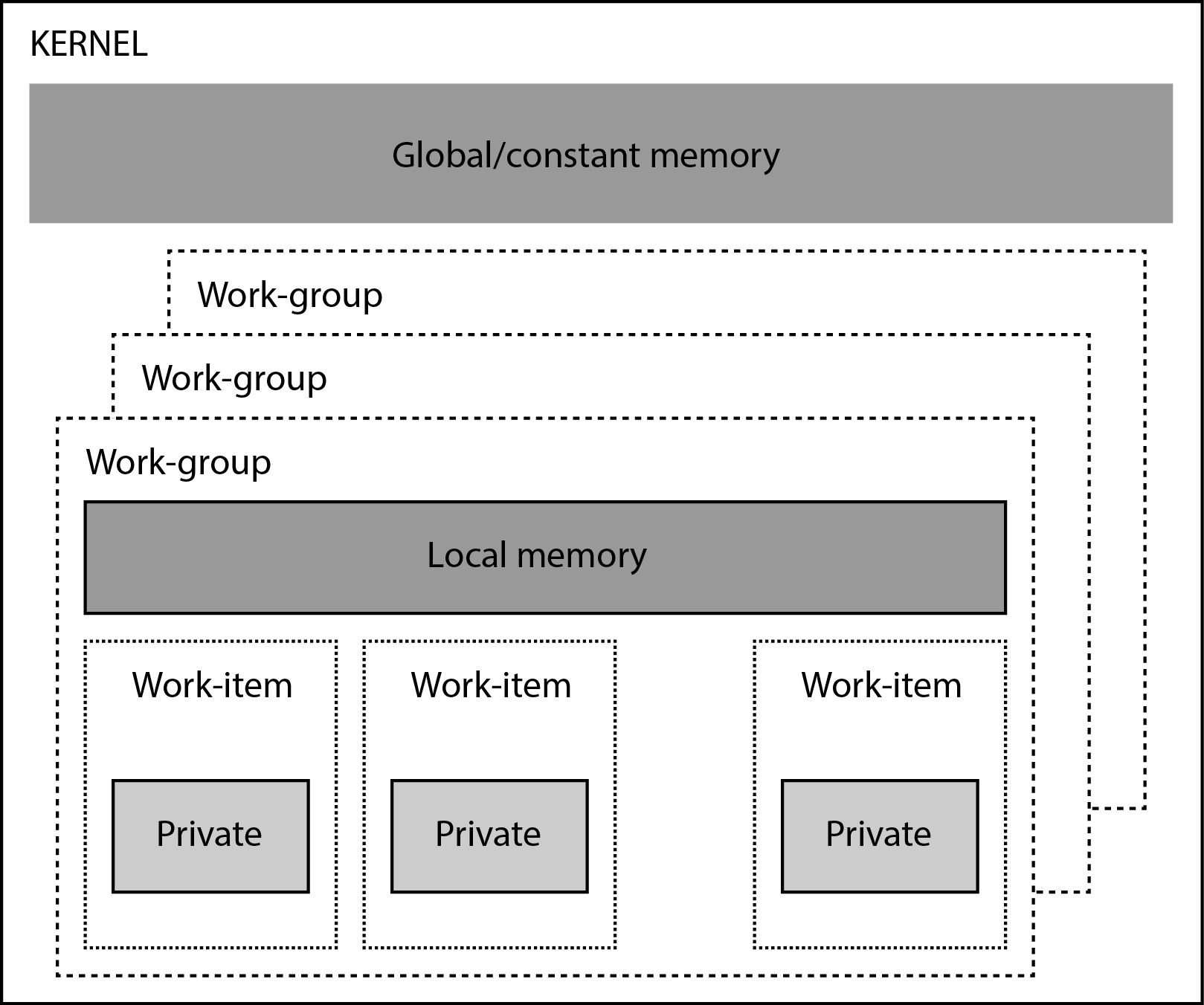
The memories provided by OpenCL are:
- We store variables in private memory that will be private for each thread. In GPU, private memory is represented by registers of arithmetic elements. If we want a variable to be private to a thread, then we need to declare it with the __private complement. In OpenCL, all variables are private by default and no add-on needs to be specified.
- We store variables in local memory that we want to be visible to all threads in the same workgroup. If we want a variable to be stored in local memory, we add the __local extension to the declaration.
- In global memory, we store variables that we want to be visible to all threads from all workgroups in the NDRange thread space. If we want a variable to be stored in global memory, we must declare it with the __global extension.
- Constant memory is the part of global memory that does not change during execution. If we want a constant to be stored in global memory, we use the __constant suffix next to the declaration.

