Text size
Line height
Text spacing
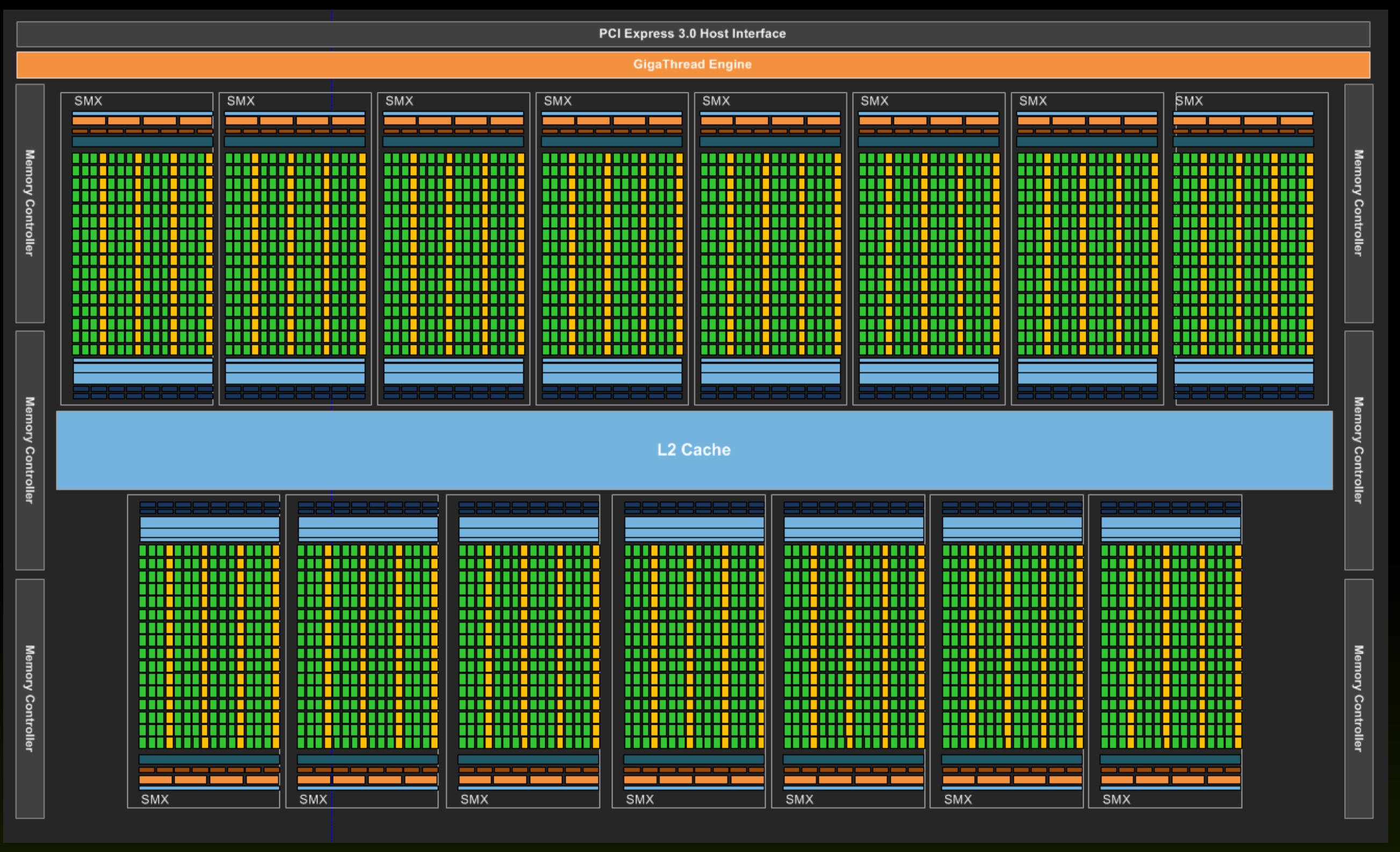
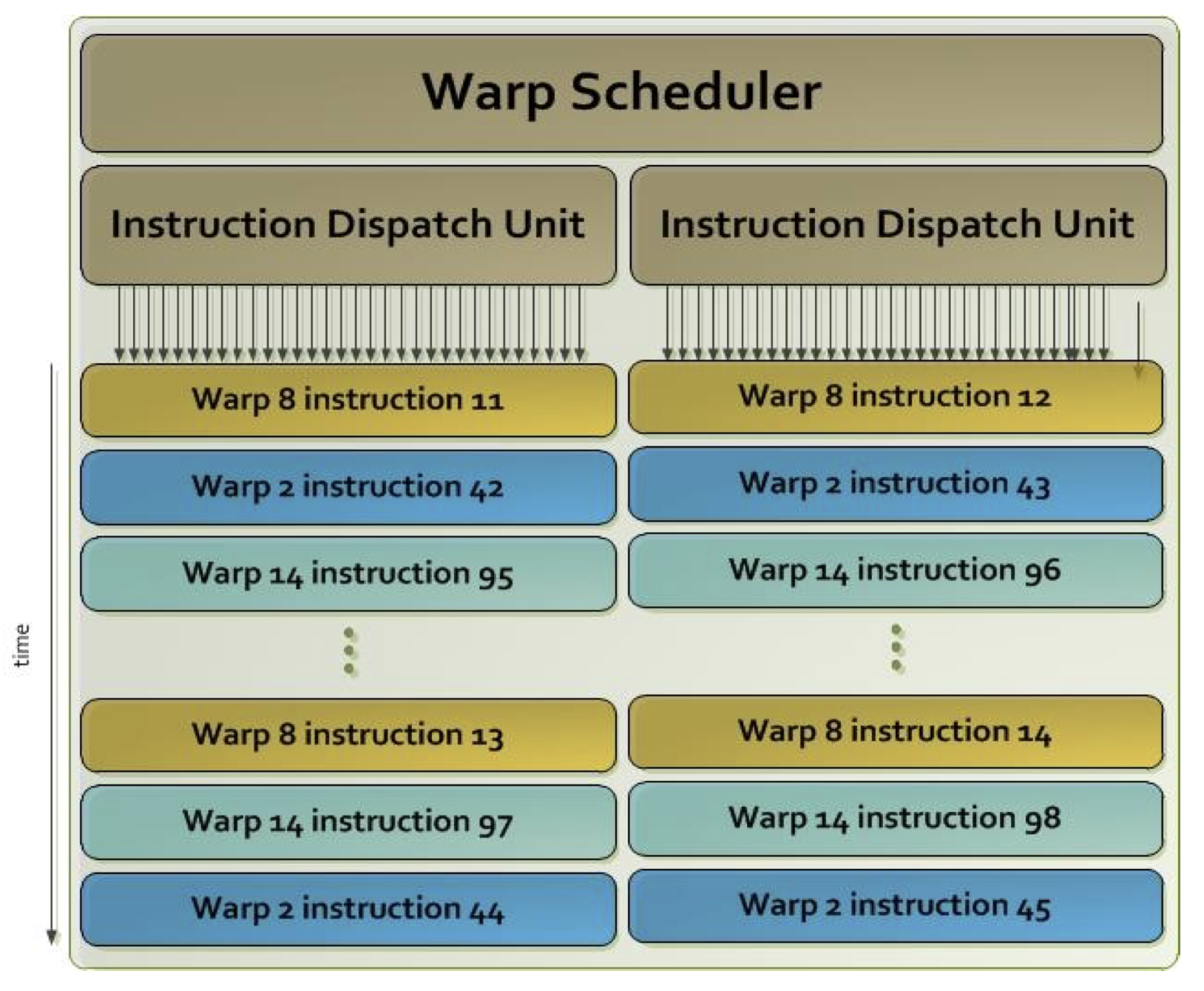
Graphical process units with a large number of process elements are ideal for accelerating problems that are data parallel. These are problems in which the same operation is performed on a large number of different data. Typical data parallel problems are computing with large vectors / matrices or images, where the same operation is performed on thousands or even millions of data simultaneously. If we want to take advantage of such massive parallelism offered to us by GPUs, we need to divide our programs into thousands of threads. As a rule, a thread on a GPU performs a sequence of operations on a particular data (for example, one element of the matrix), and this sequence of operations is usually independent of the same operations that other threads perform on other data. The program written in this way can be transferred to the GPU, where the internal sorters will arrange for sorting threads by compute units (CU) and process elements (PE). The English term for thread in the terminology used in OpenCL is work-item.
Threads are sorted on GPU in two steps:
| Limitations in Tesla K40 | |
|---|---|
| Number of threads in the bundle |
32 |
| Maximum number of beams in the calculation unit |
64 |
| Maximum number of threads in the calculation unit | 2048 |
| Maximum number of threads in group | 1024 |
| Maximum number of working groups in the calculation unit |
16 |
| Maximum number of registers per thread |
255 |
| The maximum size of local memory in the calculation unit |
48 kB |
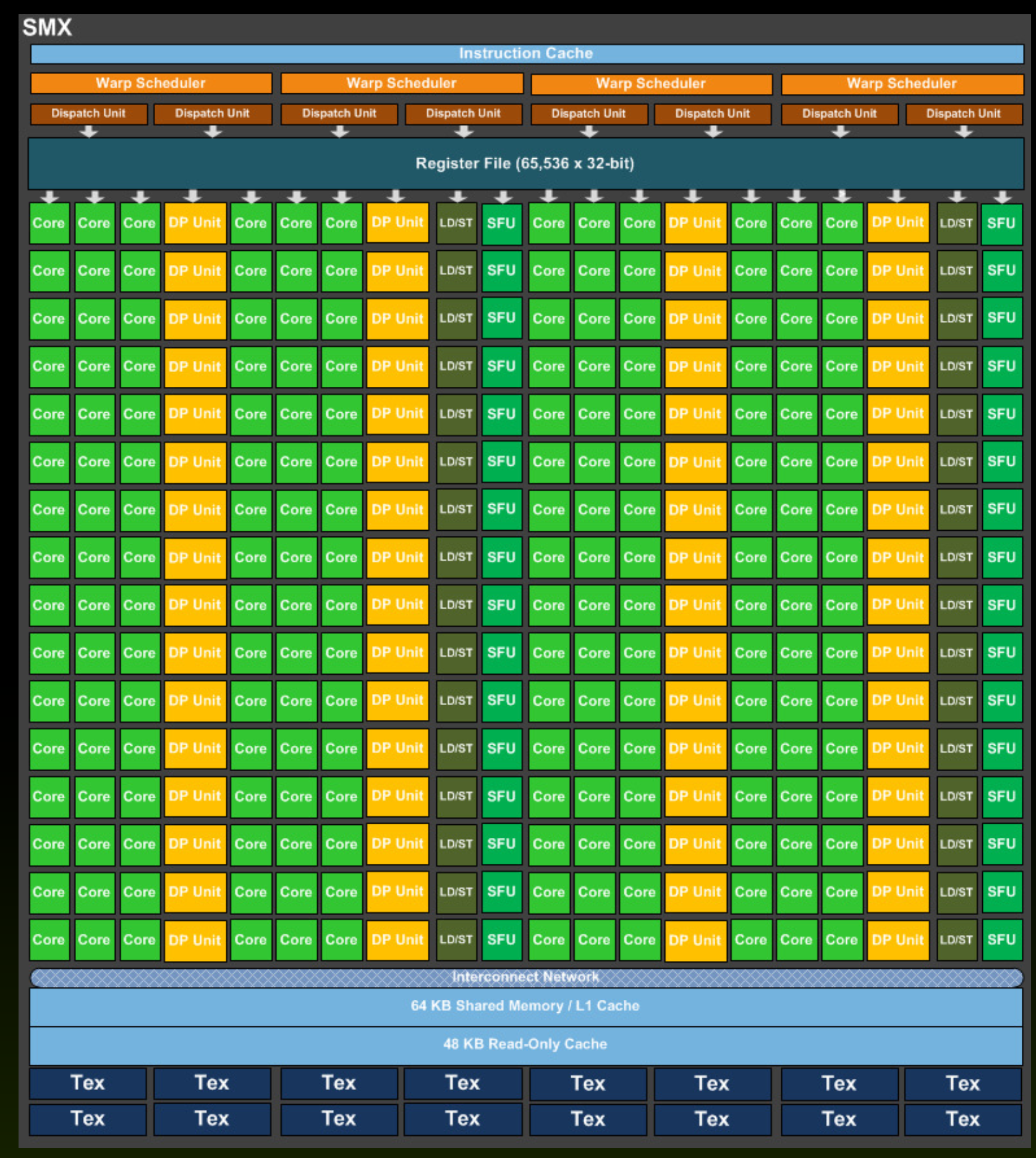
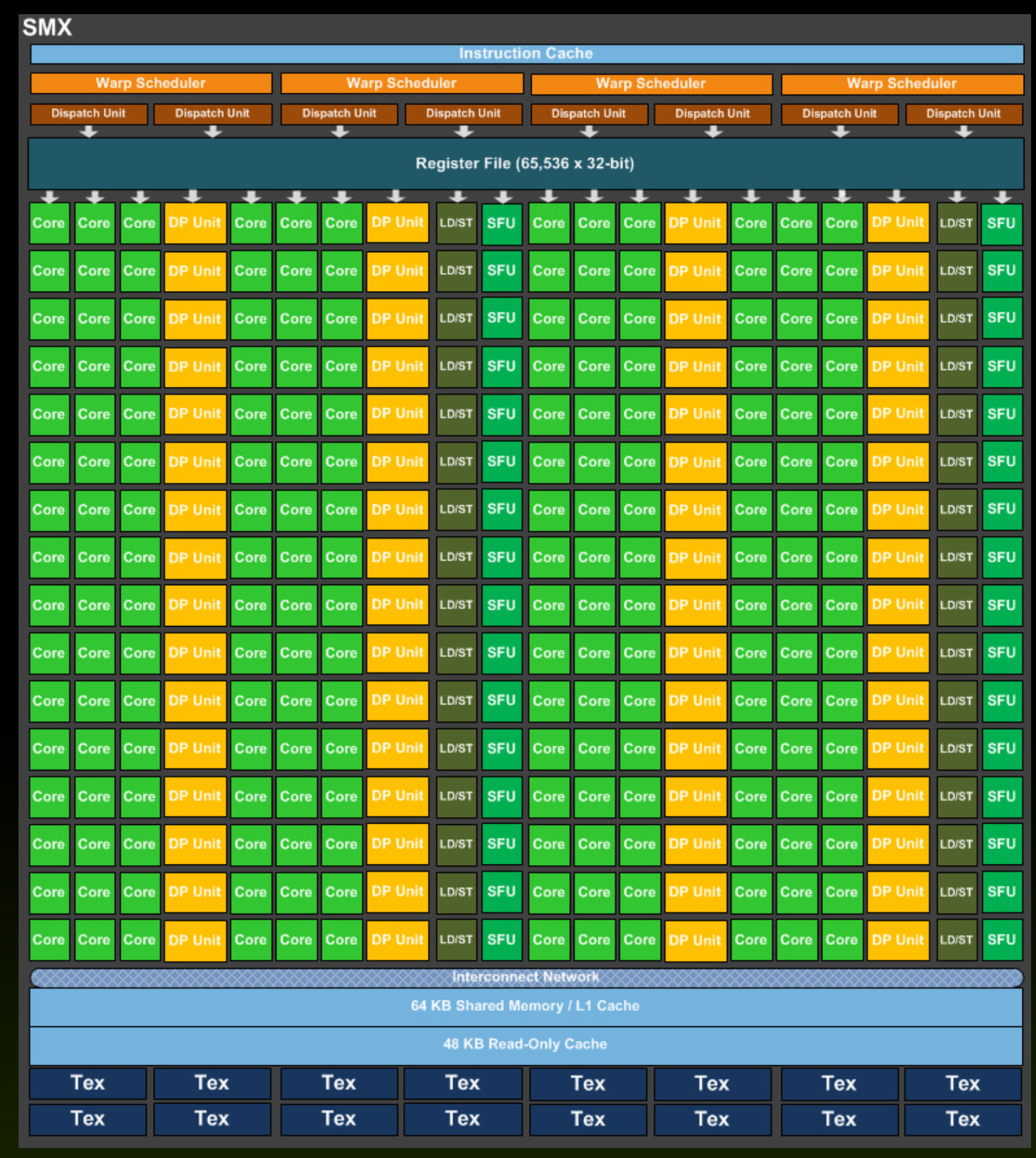
GPUs contain various memories that are accessed by individual process elements or individual threads. The image below shows the memory hierarchy on the GPU.
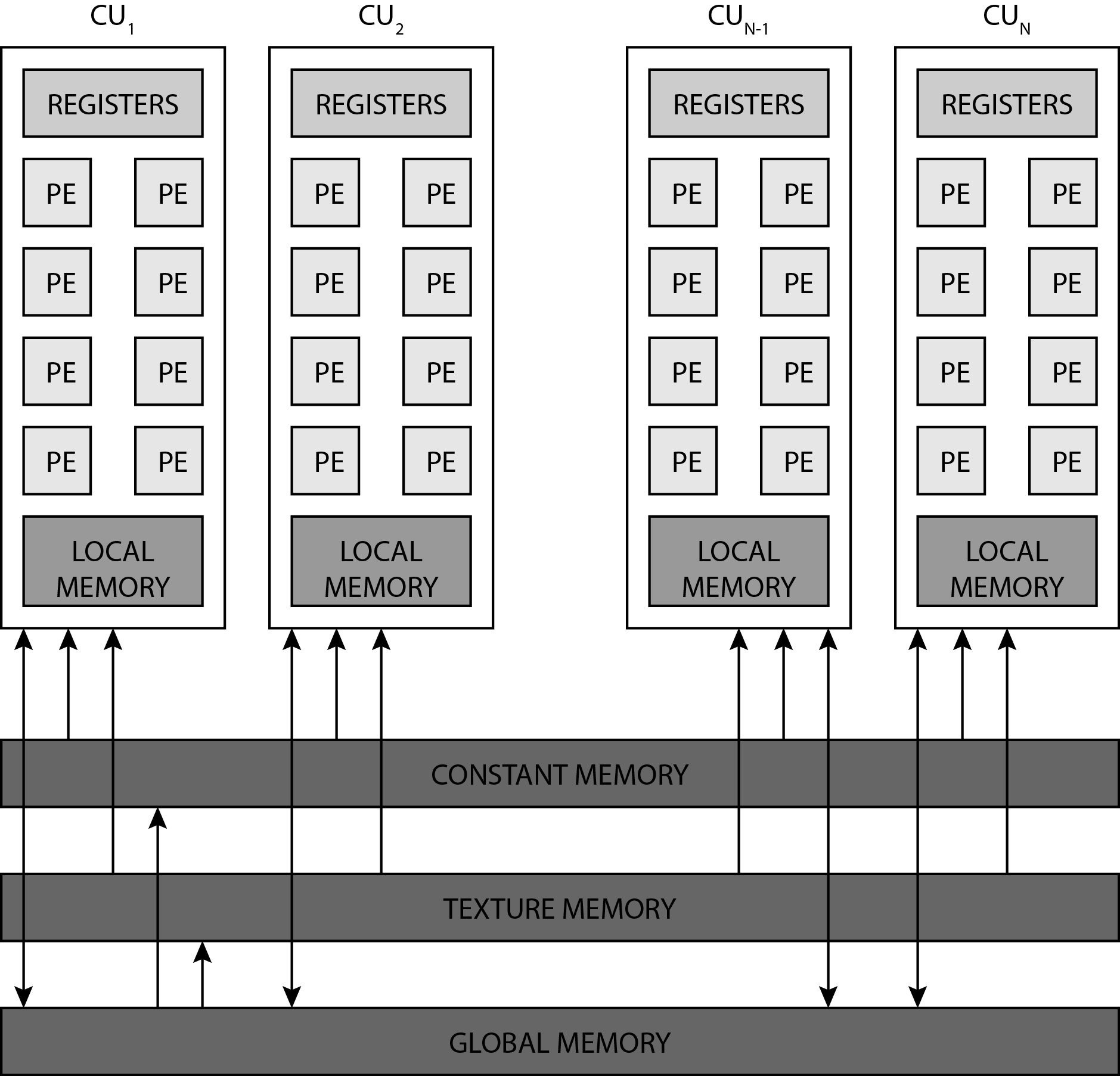
Each compute unit (CU) contains several thousand registers, which are evenly distributed among the individual threads. The registers are private for each thread. The compute unit in the Tesla K40 has 65,536 registers and each thread can use a maximum of 255 registers. Threads keep the most frequently accessed operands in the registers. Suppose we have 120 working groups with 128 threads each. On the Tesla K40 with 15 calculation units, we will have eight working groups per calculation unit (120/15 = 8), with each thread receiving up to 64 registers (65536 / (8 * 128) = 64).
Each compute unit has a small and fast SRAM (static RAM) memory, which is usually automatically divided into two parts during program startup:
With the Tesla K40 accelerator, this memory is 64kB in size and can be shared in three different ways:
As a rule, local memory is used for communication between threads within the same compute uint (threads exchange data with the help of local memory).
It is the largest memory porter on the GPU and is common to all threads and all compute units. The Tesla K40 is implemented in GDDR5. Like all dynamic memories, it has a very large access time (some 100 hour period). Access to main memory on the GPU is always performed in larger blocks or segments - with the Tesla K40 it is 128 bytes. Why segment access? Because the GPU forces the threads in the item bundle to simultaneously access data in global memory. Such access forces us into data parallel programming and has important implications. If threads in a bundle access adjacent 8-, 16-, 24-, or 32-bit data in global memory, then that data is delivered to the threads in a single memory transaction because they form a single segment. However, if only one thread from the bundle accesses a data in global memory (for example, due to branches), access is performed to the entire segment, but unnecessary data is discarded. However, if two threads from the same bundle access data belonging to two different segments, then two memory accesses are required. It is very important that when threading our programs, we ensure that memory access is grouped into segments (memory coalescing) - we try to ensure that all threads in the bundle access sequential data in memory.
Constant and texture memories are just separate areas in global memory where we store constant data, but they have additional properties that allow easier access to data in these two areas: - constant data in constant memory is always cached, this memory allows sending a single data to all threads in the bundle at once (broadcasting), - constant data (actually images) in the texture memory is always cached in the cache, which is optimized for 2D access; this speeds up access to textures and constant images in global memory.

