Let's suppoes we want to run the vectorAdd() function on one simple CPU, which is shown in the figure below. The CPU has logic for capturing and decoding commands, an arithmetic-logic unit, and a set of registers containing operands for the arithmetic-logic unit.
In addition to the CPU, the pseudo-collection code of the vectorAdd() function is shown in the figure above. We won’t go into its details, let’s just point out that the code in loop L1 is repeated 128 times.
Execution on two CPUs
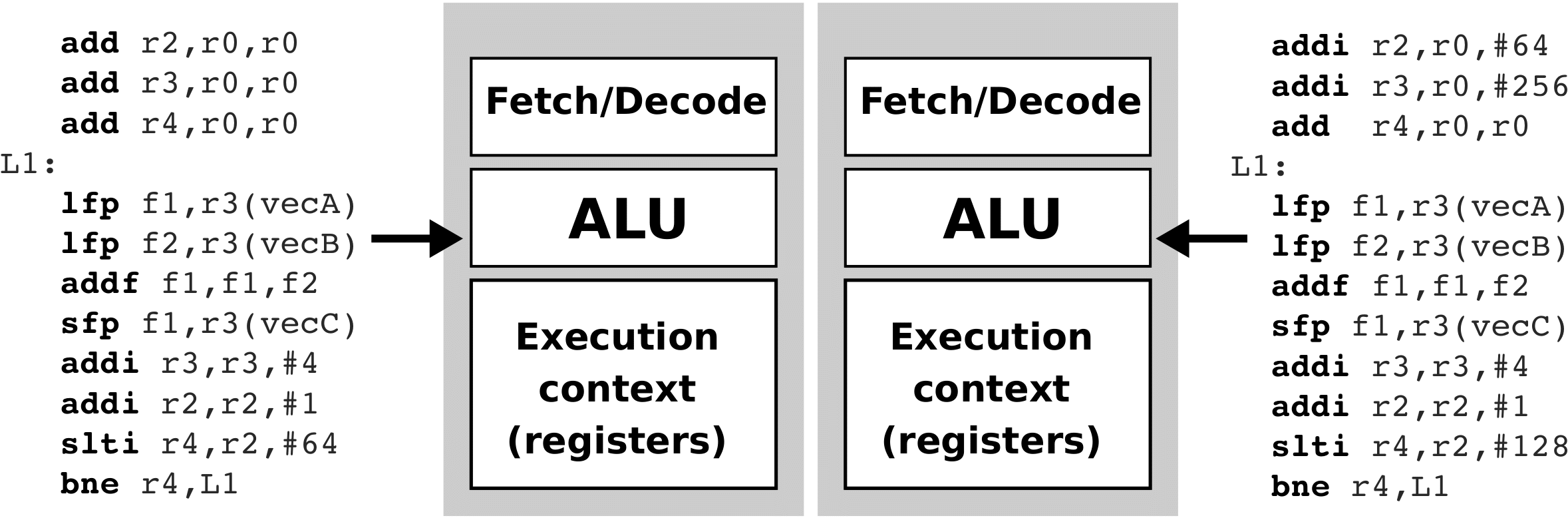
Now let's suppose we want to run the vectorAdd() function on two identical CPUs as before. The figure below shows the two CPUs and the pseudo-compiler codes running on each of these two CPUs. Again, we won’t go into the details of the collection code. Note only that the code in the L1 loop is repeated only 64 times this time, as each CPU this time adds only half of the identical elements in the vectors (the left CPU adds the first 64 elements, while the right CPU adds the last 64 elements). We can estimate that the implementation of the vectorAdd() function has been accelerated twice. We also say that two parallel threads are now running on two CPUs at the same time.
Compute unit and process elements
Let's suppose now that the upper CPU is expanded so that instead of a single arithmetic-logic unit it has eight arithmetic logic units. In addition, we add eight register strings to it, so that each arithmetic-logic unit can have its own set of registers in which to store its operands. In this way, arithmetic-logic units can calculate simultaneously, independently of each other! So, instead of replicating the entire CPU eight times, this time we only replicated its arithmetic-logic units and register string eight times. Such a CPU is shown in the figure below.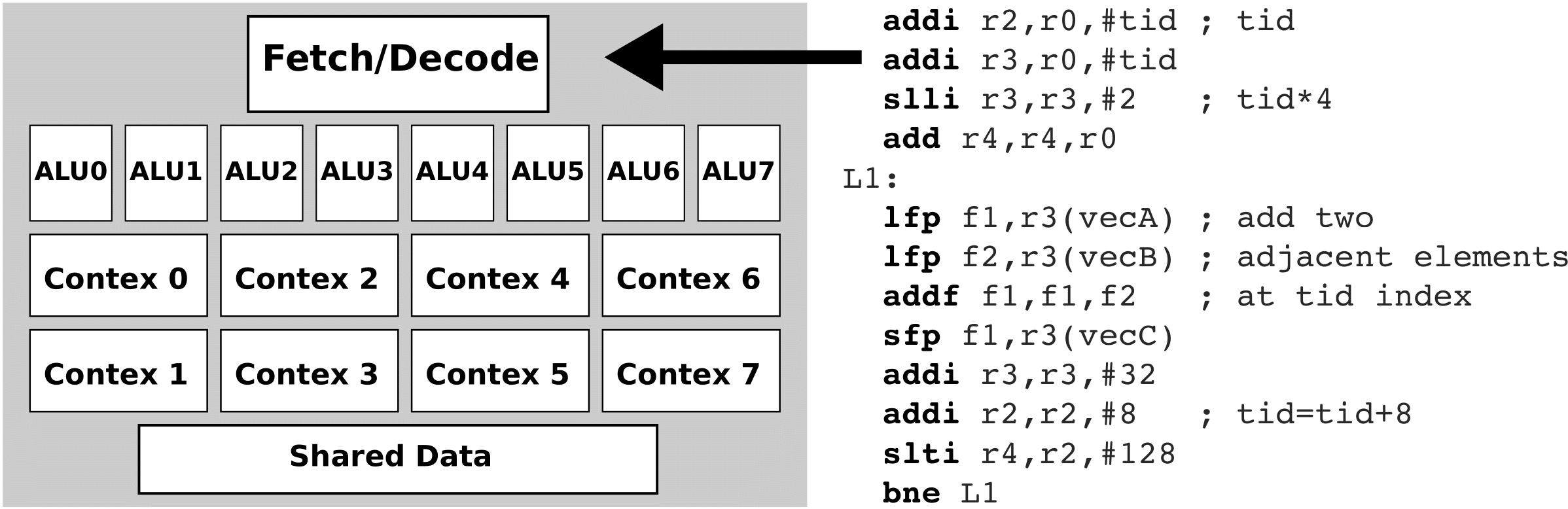
Note, however, that such a CPU still has only one unit for capturing and decoding commands - this means that it can only take over and decode one command in one clock cycle! Therefore, such a CPU will issue the same execution command to all arithmetic-logic units. However, this time the operands in the command can be vectors of length 8. This means that we will now be able to add 8 identical elements in the vector in one cycle (simultaneously) and repeat the loop only 16 times. Such a processing unit will be called a compute unit (CU). A compute unit can execute a single command over a large amount of data - in fact, in our case, a compute unit will add eight identical vector elements with just one command to read and decode. This method of implementation is called SIMD (Single Instruction Multiple Data). Because the compute unit executes each command in eight arithmetic-logic units, it looks as if different threads of the same command string are executed in arithmetic-logic units over different data. Therefore, such an implementation is also called SIMT (Single Instruction Multiple Threads). Arithmetic-logic units that execute the same command over different operands are called processing elements (PE). The figure below shows the SIMD (SIMT) execution of commands.
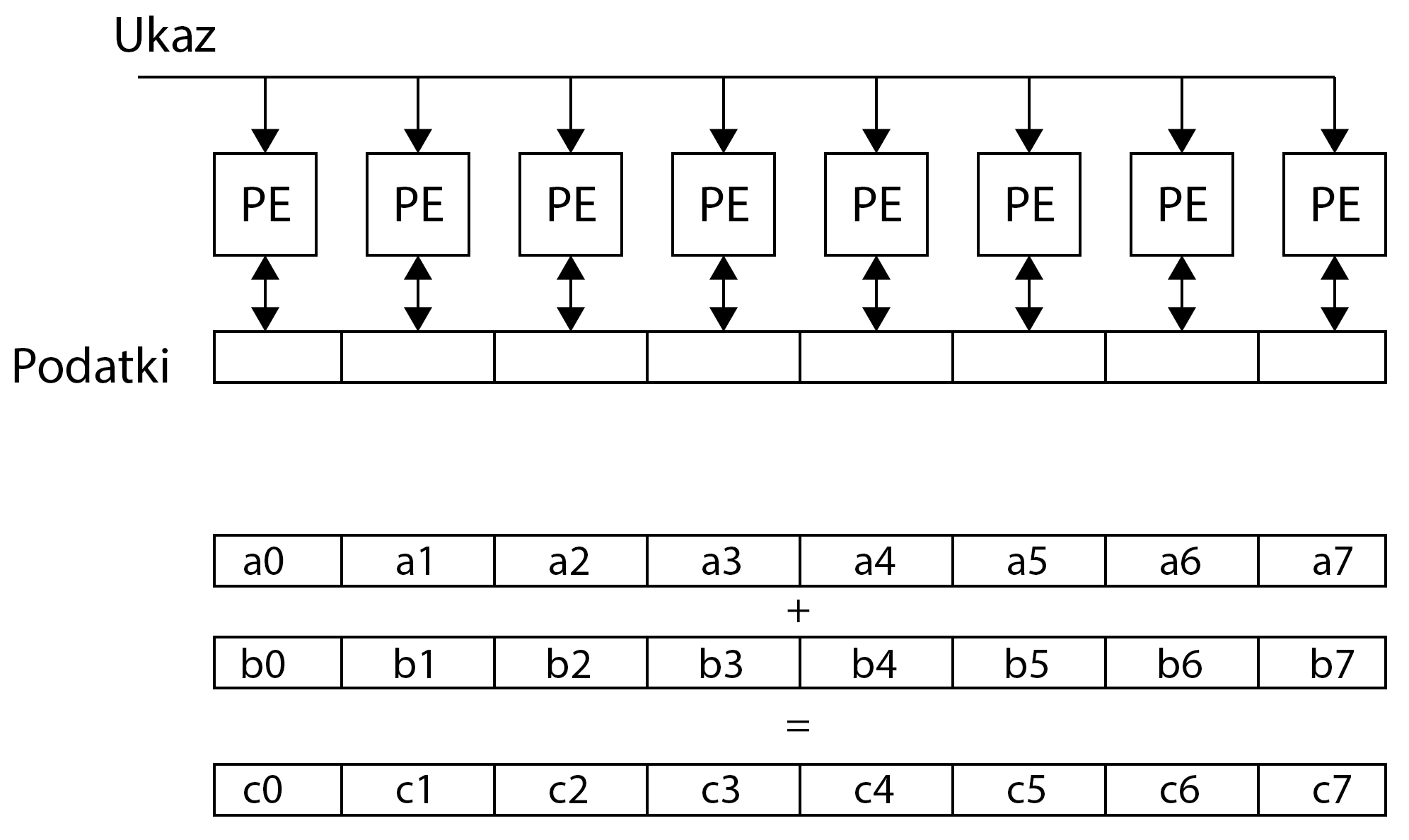
The registers in the process elements are usually private for each process element separately, which means that other process elements cannot access the data in the registers. through which they can even share data. The L1 loop is repeated only 16 times this time!
Graphic processing unit
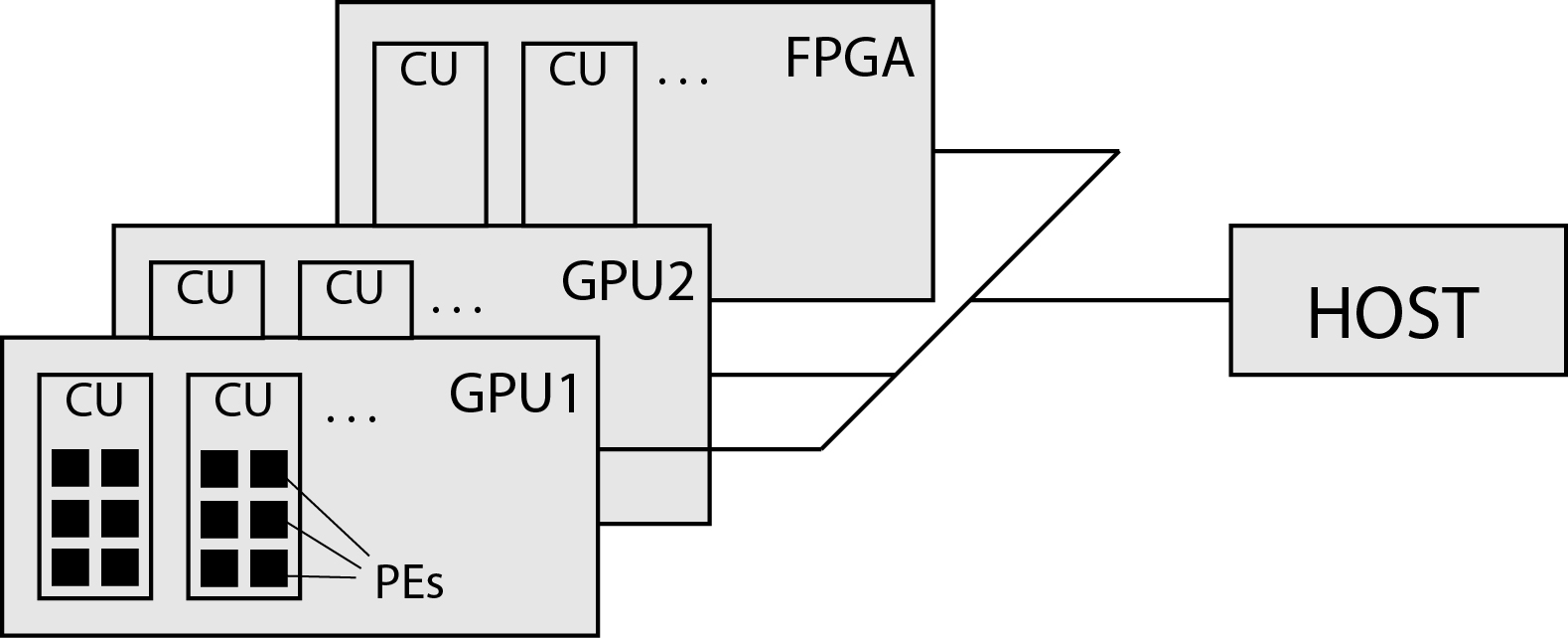
Let's take it one step further. Instead of one calculation unit in the system, we use as many as 16 calculation units, as shown in the figure below.
Now we do not have to repeat the loop 16 times but assign only one iteration of the loop to each compute unit. The figure above shows a simplified structure of graphic processing units.
Summary
Graphic processing units consist of a large number of mutually independent compute units. Compute units consist of a large number of processing elements. In a slightly simplified way, we can assume that all compute units, hereinafter referred to as CUs, execute the same program (kernel), and the process elements (PE) within one CU execute the same commands at the same time. In doing so, different CUs may perform different parts of the tongs at some point. We also say that compute units execute groups of threads, and process elements execute individual threads.