Addition of vectors
Let’s start with a simple example of adding two vectors. We will solve the problem in two ways. First, we’ll start out quite naively and focus only on the basics of GPU programming and the steps on the host that are needed to run our first program
on GPU. In the second mode, we will then focus on the kernel improvement implemented on the GPU.
The code below shows the implementation of a function in C for summing two vectors whose elements are real numbers, represented by floating-point
notation with single precision (float).
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// add the elements of two arrays
void VectorAdd(float *vecA,
float *vecB,
float *vecC,
int iNumElements) {
int iGID = 0;
while (iGID < iNumElements) {
vecC[iGID] = vecA[iGID] + vecB[iGID];
iGID += 1;
}
}
|
The arguments of the function are the addresses of all three vectors (vecA, vecB, vecC) and the number of elements in the vectors (iNumElements). The vectors are summed by summing all the identical elements in the input vectors vecA and vecB and saving
the result in the equilateral element of the vector vecC. Since the vectors have iNumElements elements, we will add the vectors in a loop that will repeat the iNumElements times.
In the loop, individual elements of the vector are indexed with
the integer index iGID. We chose the name on purpose (Global Index), the reason for such a choice will be known to us soon.
A naive attempt to add vectors
We would now like to run the VectorAdd() function on the GPU. We realized that GPUs are ideal for performing tasks where we have a lot of data parallelism - in our case this is even more true, since we perform
the same operation (addition) over all elements of vectors. In addition, these operations are independent of each other (the elements of the vectors can be summed in any order) and can thus be summed in parallel.
Kernel
In previous chapters, we learned that programs for GPU (kernels) are written in such a way that they can be executed (simultaneously) by all threads from the NDRange space (this will of course be defined below) - these are all threads
that will be run on GPU . Therefore, we need to divide the work done by the VectorAdd() function as evenly as possible between the threads. In our case, this is a fairly simple task, as we will divide the work to begin with so that each thread will
add only the same elements. Therefore, we will run as many threads on the GPU as there are elements in the vectors - in our case, this is the iNumElements thread.
All the iNumElements threads that we will run are made up of NDRange space. We
have already mentioned that this space can be one-, two-, or three-dimensional and that we adjust the dimension of the space to the data. Since our vectors are one-dimensional fields, we will organize the NDRange space in our case in one dimension
(X). The global size of this space will be iNumElements. Therefore, the global index of each thread that will run on the GPU will be uniquely determined from that space and will actually correspond to the index of the elements that the thread adds
up. The kernel that all threads will run on the GPU is shown in the code below:
1
2
3
4
5
6
7
8
9
10
11
12
|
__kernel void vecadd_naive (
__global float* vecA,
__global float* vecB,
__global float* vecC,
int iNumElemements){
int iGID = get_global_id(0);
if (iGID < iNumElemements) {
vecC[iGID] = vecA[iGID] + vecB[iGID];
}
}
|
We see that the kernel code is very similar to the VectorAdd() function code. Each function we want to perform on the GPU must be declared as a kernel (__kernel). We named the kernel vecadd_naive (), and its arguments are the titles of the vectors and
the number of elements in the vectors. The vector addresses this time have the __global specifier, which determines that these addresses refer to the global memory on the GPU. The vectors we want to add to the GPU must be stored on the GPU, because
the compute units on the GPU cannot address the main memory on the host. Because vectors can be quite large, global memory is the only suitable memory space for storing vectors. In addition, all compute units can address global memory and therefore
the vector elements will be accessible to all threads, regardless of which compute unit each thread will run on (we have no influence on this anyway).
Each thread first determines its global iGID index in the NDRange space with the get_global_id(0)
function. Argument 0 when calling a function specifies that we require an index in dimension X. Then each thread sums identical elements in vectors whose index is equal to its index, but only if its index is less than or equal to the number of elements
in vectors (so in a kernel if sentence). In this way we provide two:
- the data with which each thread works are uniquely determined for each thread and there is no possibility that two threads might try to write to the same element of the vector vecC,
- memory access is grouped into segments where all threads in the same bundle access sequential 8-, 16-, 24-, or 32-bit data in memory (memory coalescing).
Now all we have to do is look at how to translate such a kernel for the selected GPU device and how to transfer it to the GPU and run it there.
A detailed description of the OpenCL C programming language can be found on
The OpenCL C Specification website.
Host program
Once we have written the kernel, we need to translate it first. We translate the pins for the selected device, so we must first select the platform, the device within the platform, create the context and command line for each
device as we learned in the previous chapter. With this, the work of the program on the host is far from over. The latter must now perform the following tasks:
- reserve space in main memory and initialize data on the host,
- reserve space in the device's global memory where we will store our vectors,
- read the device application from file to memory,
- compile a device program - the device program will be translated during the execution of the program on the host,
- create a kernel from the translated program, which we will run on the selected device,
- transfer data from the host to the device
- set kernel arguments,
- set the size and organization of the NDRange thread space,
- run the kernel on the device and
- read data from the global memory on the device after the kernel execution is complete.
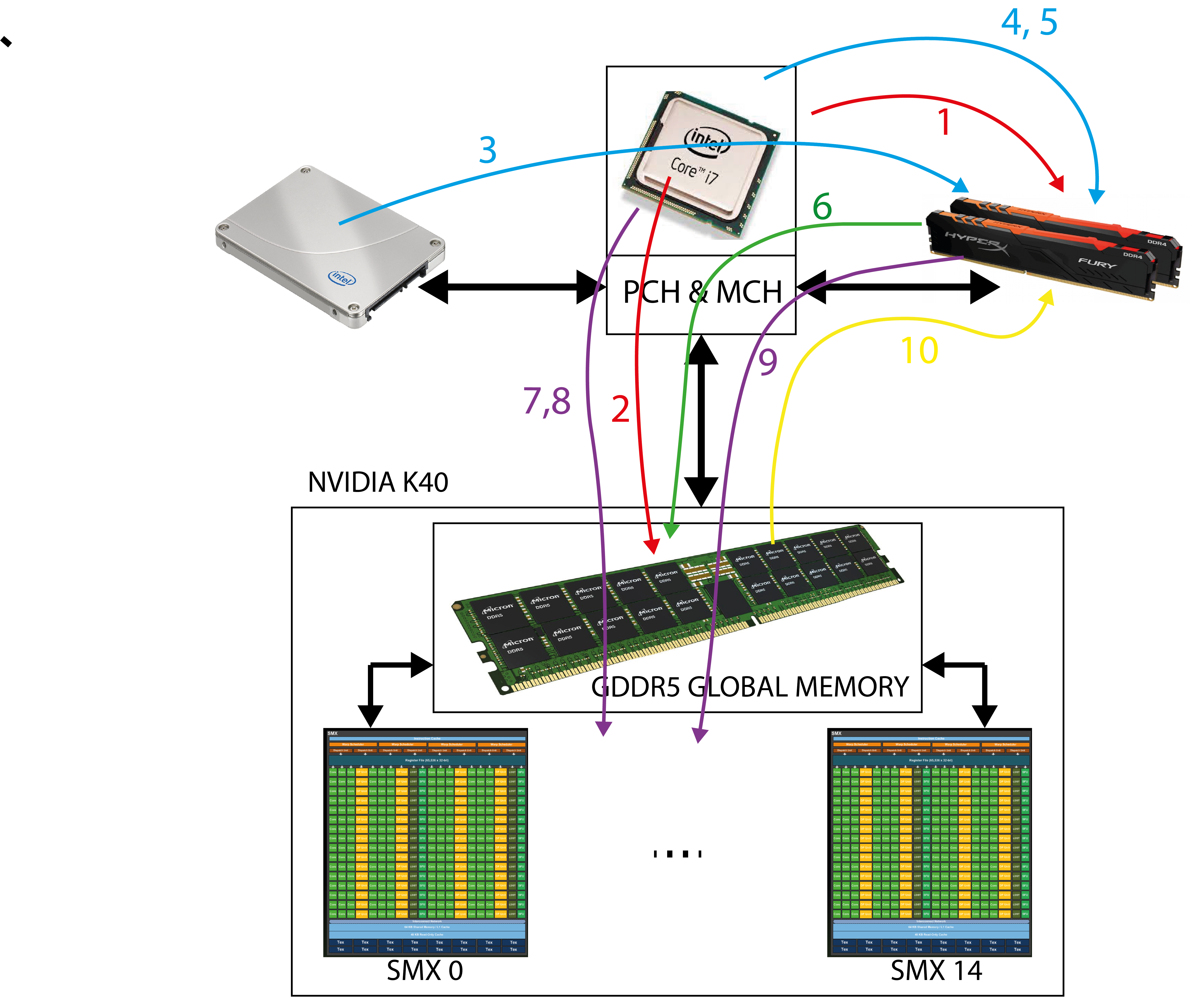
The image above shows all the steps that a program must perform on the host before and after running the pins on the GPE device.
Initialize data on the host
The program on the host must initialize all the data needed to compute on the device. We need to be aware that the host can only access its main memory and for now, all the data initialized by the host will
be in the main memory. In our case, we need to reserve space for all three vectors and initialize the vectors we want to add:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
cl_float* vecA_h;
cl_float* vecB_h;
cl_float* vecC_h;
int iNumElements = 256*4; // works for vectors with up to 1024 elements
// Allocate host arrays
vecA_h = (void *)malloc(sizeof(cl_float) * iNumElements);
vecB_h = (void *)malloc(sizeof(cl_float) * iNumElements);
vecC_h = (void *)malloc(sizeof(cl_float) * iNumElements);
// init arrays:
for (int i = 0; i<iNumElements; i++ ) {
vecA_h[i] = 1.0;
vecB_h[i] = 1.0;
}
|
We added _h to the names of the vectors we store on the host to emphasize that this is the data on the host. All elements of the input vectors on the host were set to 1.
Reserve space in the device's global memory
We now need to reserve space in the device’s global memory where we will store all the vectors that occur in the computation. We use the clCreateBuffer() function to reserve space in the device's
global memory. This reserves a datasize size space. When reserving space in the global memory, specify whether the device will only read from the reserved space (CL_MEM_READ_ONLY), only write to it (CL_MEM_WRITE_ONLY) or will have read and write access
(CL_MEM_READ_WRITE). The clCreateBuffer() function returns a handler (type cl_mem) to a memory object (reserved space) in the device's global memory.
Remember that the host (CPU) does not have direct access to this memory so never try to use this handler as a pointer and dereference it to the host!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39 | //***************************************************
// Create device buffers
//***************************************************
cl_mem vecA_d; // Input array on the device
cl_mem vecB_d; // Input array on the device
cl_mem vecC_d; // Output array on the device
// Size of data:
size_t datasize = sizeof(cl_float) * iNumElements;
// Use clCreateBuffer() to create a buffer object (d_A)
// that will contain the data from the host array A
vecA_d = clCreateBuffer(
context,
CL_MEM_READ_ONLY,
datasize,
NULL,
&status);
clerr_chk(status);
// Use clCreateBuffer() to create a buffer object (d_B)
// that will contain the data from the host array B
vecB_d = clCreateBuffer(
context,
CL_MEM_READ_ONLY,
datasize,
NULL,
&status);
clerr_chk(status);
// Use clCreateBuffer() to create a buffer object (d_C)
// with enough space to hold the output data
vecC_d = clCreateBuffer(
context,
CL_MEM_WRITE_ONLY,
datasize,
NULL,
&status);
clerr_chk(status);
|
Reading kernel
Kernels are written in files with the .cl extension. In our case, the kernel.cl file will only contain a kernel of vecadd_naive(). In general, the kernel.cl file could contain any number of pliers and the functions that these pins call. We need to compile the program for the selected device, so we do this when the host already has all the information about the platform and devices. Before compiling, we need to read the program from the kernel.cl file into the host memory and then create a program object suitable for translation from it. We do this with the code below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35 | //***************************************************
// Create a program object for the context
//***************************************************
FILE* programHandle; // File that contains kernel functions
size_t programSize;
char *programBuffer;
cl_program cpProgram;
// 6 a: Read the OpenCL kernel from the source file and
// get the size of the kernel source
programHandle = fopen("kernel.cl", "r");
fseek(programHandle, 0, SEEK_END);
programSize = ftell(programHandle);
rewind(programHandle);
printf("Program size = %lu B \n", programSize);
// 6 b: read the kernel source into the buffer programBuffer
// add null-termination-required by clCreateProgramWithSource
programBuffer = (char*) malloc(programSize + 1);
programBuffer[programSize] = '\0'; // add null-termination
fread(programBuffer, sizeof(char), programSize, programHandle);
fclose(programHandle);
// 6 c: Create the program from the source
//
cpProgram = clCreateProgramWithSource(
context,
1,
(const char **)&programBuffer,
&programSize,
&status);
clerr_chk(status);
free(programBuffer);
|
First we open the kernel.cl file and read the code from it and save it as a sequence of characters in the program string Buffer. Only then, with the clCreateProgramWithSource() function, do we read the programBuffer character string and create the appropriate translation object cpProgram from it.
Compile the program for the selected GPE device
The translation of the read program, which is stored in the cpProgram object, is translated with the clBuildProgram() function, as shown in the code below.
1
2
3
4
5
6
7
8
9
10
11
12 | //***************************************************
// Build the program
//***************************************************
status = clBuildProgram(
cpProgram,
0,
NULL,
NULL,
NULL,
NULL);
clerr_chk(status);
|
We must be aware that only now, ie during the execution of the program on the host, the kernel, which we read from the kernel.cl file, is translated. Any errors in the code in kernel.cl will only appear now, during translation, and not when compiling the host program. Therefore, in the event of translation errors (for the clBuildProgram() function), they must be stored in a data set in main memory and displayed if necessary. This can be done with the clGetProgramBuildInfo() function:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29 | if (status != CL_SUCCESS)
{
size_t len;
printf("Error: Failed to build program executable!\n");
// Firstly, get the length of the error message:
status = clGetProgramBuildInfo(cpProgram,
devices[0],
CL_PROGRAM_BUILD_LOG,
0,
NULL,
&len);
clerr_chk(status);
// allocate enough memory to store the error message:
char* err_buffer = (char*) malloc(len * sizeof(char));
// Secondly, copy the error message into buffer
status = clGetProgramBuildInfo(cpProgram,
devices[0],
CL_PROGRAM_BUILD_LOG,
len * sizeof(char),
err_buffer,
NULL);
clerr_chk(status);
printf("%s\n", err_buffer);
free(err_buffer);
exit(1);
}
|
The clGetProgramBuildInfo() function is called twice. First, to determine the length of the error message, and second, to read the entire error message. The following is an example of an error printout in the case where we used an undeclared name for vector B in a kernel:
Error: Failed to build program executable!
<kernel>:9:35: error: use of undeclared identifier 'vecBB'; did you mean 'vecB'?
vecC[myID] = vecA[myID] + vecBB[myID];
^~~~~
vecB
<kernel>:2:33: note: 'vecB' declared here
__global float* vecB,
^
Creating a kernel from a translated program
In general, our translated program could contain more kernels. So now we only create a kernel of vecadd_naive() from the program that we want to run on the device. We do this with the clCreateKernel() function.
| //***************************************************
// Create and compile the kernel
//***************************************************
cl_kernel ckKernel;
// Create the kernel
ckKernel = clCreateKernel(
cpProgram,
"vecadd_naive",
&status);
clerr_chk(status);
|
Data transfer to the device
The vectors that we initialized in the first step are transferred from the host's main memory to previously created memory objects in the device's global memory. Data transfer is actually triggered by writing the appropriate command to the cmdQueue device command line. We do this with the clEnqueueWriteBuffer() function.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30 | //***************************************************
// Write host data to device buffers
//***************************************************
// Use clEnqueueWriteBuffer() to write input array A to
// the device buffer bufferA
status = clEnqueueWriteBuffer(
cmdQueue,
vecA_d,
CL_FALSE,
0,
datasize,
vecA_h,
0,
NULL,
NULL);
clerr_chk(status);
// Use clEnqueueWriteBuffer() to write input array B to
// the device buffer bufferB
status = clEnqueueWriteBuffer(
cmdQueue,
vecB_d,
CL_FALSE,
0,
datasize,
vecB_h,
0,
NULL,
NULL);
clerr_chk(status);
|
Setting kernel arguments
In order to run the selected kernel vecadd_naive(), we need to set arguments to it. To do this, use the clSetKernelArg() function.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22 | //***************************************************
// Set the kernel arguments
//***************************************************
// Set the Argument values
status = clSetKernelArg(ckKernel,
0,
sizeof(cl_mem),
(void*)&vecA_d);
status |= clSetKernelArg(ckKernel,
1,
sizeof(cl_mem),
(void*)&vecB_d);
status |= clSetKernelArg(ckKernel,
2,
sizeof(cl_mem),
(void*)&vecC_d);
status |= clSetKernelArg(ckKernel,
3,
sizeof(cl_int),
(void*)&iNumElements);
clerr_chk(status);
|
The second argument of the clSetKernelArg() function indicates the order of the argument when the clip is called.
Setting up and organizing the NDRange space
We are just about to run the threads that will execute the selected kernel on the GPU device. We still need to determine how many threads we will run on the GPU device, how these threads will be organized into workgroups, and how the threads and workgroups will be organized in the NDRange space. We call this the NDRange space setting. For now, we will be working in the one-dimensional NDRange space, so its size and organization are determined by the following variables szLocalWorkSize and szGlobalWorkSize:
| // set and log Global and Local work size dimensions
const size_t szLocalWorkSize = 128;
const size_t szGlobalWorkSize = iNumElements;
|
In the code above, we specified that we want to have 128 threads in the workgroup and that we want to run as many threads as the long vectors (iNumElements).
Launch the kernel on the selected GPU device
To start the kernel on the selected device, write the command to run the kernel and the description of the NDRange space in the cmdQueue command line. We do both with the clEnqueueNDRangeKernel() function.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 | //***************************************************
// Enqueue the kernel for execution
//***************************************************
// Launch kernel
status = clEnqueueNDRangeKernel(
cmdQueue,
ckKernel,
1,
NULL,
&szGlobalWorkSize,
&szLocalWorkSize,
0,
NULL,
NULL);
clerr_chk(status);
|
In the code above, we said that we want to run a kernel of ckKernel, that the NDRange space has dimension 1, that its global size is szGlobalWorkSize, and that the threads are organized into szLocalWorkSize size workgroups.
At this point, it should be noted that when we stop a command in the command line (for example, to transfer data or run a kernel), we have no influence on when the command will actually be executed. The clEnqueueWriteBuffer() and clEnqueueNDRangeKernel() functions are non-blocking and terminate immediately. So we don’t really know when the data will be transferred, when the kernel starts and ends running on the device. The type only provides us with the order of execution of commands in it. Thus, we can argue that the kernel will certainly not start running until the data is transferred from the host to the device.
Reading data from GPU device
When the kernel is complete, the vector with the sums is transferred from the device's global memory to the host's main memory.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20 | //***************************************************
// Read the output buffer back to the host
//***************************************************
// Synchronous/blocking read of results
status = clEnqueueReadBuffer(
cmdQueue,
vecC_d,
CL_TRUE,
0,
datasize,
vecC_h,
0,
NULL,
NULL);
clerr_chk(status);
// Block until all previously queued OpenCL commands in a command-queue
// are issued to the associated device and have completed
clFinish(cmdQueue);
|
But how do we now know when the data will actually be copied and when we can access it? To do this, call the clFinish() function, which blocks the execution of the main program until the cmdQueue command type is emptied.
Erasing memory on the host
At the end of the program, we still need to free up all the reserved memory space on the host.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20 | //*************************************************
// Cleanup
//*************************************************
if (srcA_h) free(vecA_h);
if (srcB_h) free(vecA_h);
if (srcC_h) free(vecA_h);
if (platforms) free(platforms);
if (devices) free(devices);
if(ckKernel) clReleaseKernel(ckKernel);
if(cpProgram) clReleaseProgram(cpProgram);
if(cmdQueue) clReleaseCommandQueue(cmdQueue);
if(context) clReleaseContext(context);
if(srcA_d) clReleaseMemObject(srcA_d);
if(srcB_d) clReleaseMemObject(srcB_d);
if(srcC_d) clReleaseMemObject(srcC_d);
|
The full code from this chapter can be found in the 02-vector-add-short folder here.
Addition of arbitrarily long vectors
The vecadd_naive() kernel we used to add the vectors has one drawback - each thread that the vecadd_naive() kernel performs will calculate only one sum. Recall that the number of threads that make up a workgroup is limited and that the number of threads that run simultaneously on one unit of account is also limited. With the Tesla K40 device, the maximum number of threads that are executed on one calculation unit at a time is 2048. Since the Tesla K40 device has only 15 calculation units, the maximum number of threads that can be executed at one time is 30,720. If we run more than that many threads, the driver will have to serialize their execution on the GPU. Therefore, it is much better to determine the maximum number of threads that we run from how many threads we will put in one workgroup, how many groups can be executed on one unit of account at a time, and how many units of account are on the GPU. In this case, we will probably have a smaller number of threads than the length of the vectors. We solve the problem with the bottom kernel.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 | __kernel void VectorAdd_arbitrary(__global float* vecA,
__global float* vecB,
__global float* vecC,
int iNumElements) {
// get index into global data array
int iGID = get_global_id(0);
int iGS = get_global_size(0);
while (iGID < iNumElements) {
//add the vector elements
vecC[iGID] = vecA[iGID] + vecB[iGID];
iGID = iGID + iGS;
}
}
|
Now, each thread will first determine its global iGID index and the global size of the NDRange iGS space (this is actually the number of all active threads). It will then add the identical elements in the while loop by adding two identical elements in one iteration and then increasing the iGID by as many as all the active threads. Thus, it will move to the next two identical elements and add them up. The loop ends when the iGID index exceeds the size of the vectors.
Surely you are wondering why one thread would not add up an adjacent pair of identical elements or 4 adjacent pairs of identical elements? The reason lies in the memory access mode! Recall that memory is accessed in segments. To ensure coordinated memory access, two adjacent threads in the bundle must access two adjacent memory words.
The program on the host stays the same this time - only the second kernel needs to be loaded. You can also try to play with different vector sizes and different NDRange space settings yourself.
The full code from this chapter can be found in the 04-vector-add-arb folder
here.